Python 強化學習 AI 訓練-貪吃蛇
Python 強化學習 AI 訓練-貪吃蛇
資料
計算機概論 期末專題
作者:王冠章
學號:C14116132
Github 連結:https://github.com/z-hwa/AITraining
目錄
一、摘要
二、開發環境
三、主要套件
四、遊戲本體
五、AI 實現
六、模型訓練成效
七、操作與介面說明
八、專案總結
九、未來規劃
十、參考資料一、摘要:
利用 python 中的 pygame 套件,先實作貪吃蛇遊戲,完成玩家操控的部分。接著完成 AI 的 agent 對於遊戲操控、收集遊戲中資料的程式碼。最後,透過 pytorch 中的 Linear 實現模型的訓練框架,以及 optim 來優化 AI訓練對於獎勵獲取的算法。也實作了操作介面,方便 AI 訓練的操作以及實際測試。
二、開發環境:
Pycharm
Powewshell 7.6
github
Python3.7
Pytorch with cpu
Conda
三、主要套件:
Pygame
matplotlib ipython
numpy
四、遊戲本體:
貪吃蛇遊戲本體的實現,是由數個函數來完成,以下說明與 AI 較為相關的數個。
(一) Reset
用於初始化遊戲的資料設定,如蛇的數據、食物、分數等等資訊。
之所以不寫在 init 中的原因是,AI 訓練時會需要反覆開啟遊戲的
新局,因此可以直接呼叫此函數。
(二) _play_step
除了作為玩家輸入之外,在 AI 訓練中,將改為從模型中取得輸
出。而因為遊戲的進行是基於玩家的操控,在此函數中,同時呼叫
是否發生碰種、移動、ui 更新的函數。
(三) _move
移動的實現是透過計算蛇頭的下一個位置,並在 list 中插入。而
原先的尾巴則會被清掉。在更新 UI 時,透過 pygame 根據 list 中
的座標去繪製方塊,形成蛇的移動。
五、AI 實現:
關於參考資料中的模型,包含 11 個輸入層、256 個隱藏層、3 個輸出層。11 個輸入層的資料分別為
(一) 轉向是否會產生碰種,包含左轉、右轉、不轉。
(二) 頭部相鄰的四個方格,是否存在障礙物。
(三) 食物的位置是在上下左右哪個方位。
這些資料都是 0 或 1 的整數型資料。而輸出層則會輸出 3 個浮點數,並從這三個浮點數中,取出最大值,作為貪吃蛇行動的根據,包括:左轉、右轉、不轉。
而模型則透過 Q learning 來訓練,第一步會透過現在的狀態去預測 Q值,執行動作,計算獎勵,最後計算出新的 Q 值。從代碼實現的角度來看,我們最終會得到一個動作回數*3 行動可能的 Q 值表,並利用 pytorch寫好的優化函數,來幫我們更新模型的參數。如下
# 1. 透過現在的狀態去預測Q值
pred = self.model(state)
# 2. Q_new = r + y * max(next_predicted Q value) -> only do this if not done
# pred.clone()
# preds[argmax(action)] = Q_new
target = pred.clone() # 複製前面的預測
for idx in range(len(done)):
Q_new = reward[idx] # 預設新的Q值為當前編號的reward
# 如果done為false(遊戲還沒結束,可以預測下一個行動)
if not done[idx]:
Q_new = reward[idx] + self.gamma * torch.max(self.model(next_state[idx])) # 藉由公式計算新的Q值
target[idx][torch.argmax(action).item()] = Q_new # 將運測中行動可能性最高的設為新的Q值代碼中有一個數值叫做 gamma,實際上代表的是折扣率,介於 0~1 之間。用於讓 AI 能夠判斷是要更關注未來(數值高)還是現在的獎勵(數值低)。
而在 AI 訓練時,最終的行動決策上,則取決於 epsilon 以及 random 的比較,來決定這一次的行動是隨機發生,或著是由 AI 模型的預測結果去進行。隨著訓練局數的增加,將降低隨機選擇動作的機率,來優化 AI 模型的精準度。
六、模型訓練成效:
可以在recode_model_train中查看訓練的模型紀錄,並在model中找到對應的AI模型;figure中找到對應的訓練圖表。在更新舊模型訓練後,進行訓練的AI模型,可以在data中找到當時的訓練資料。
(一)參考資料模型配置:
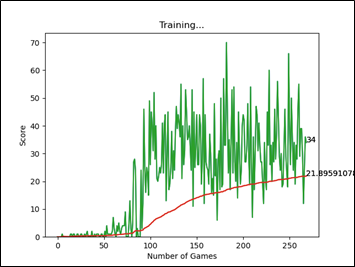
圖二、訓練250回左右的AI得分圖表
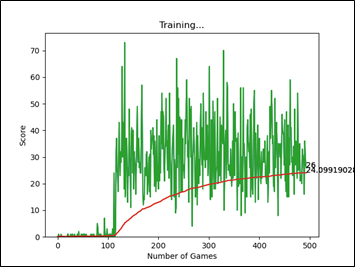
圖三、訓練500回左右的AI得分圖表
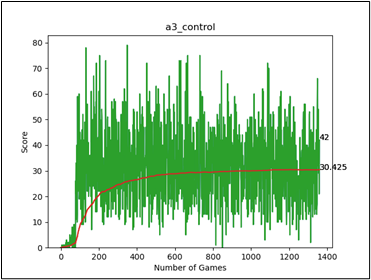
圖四、訓練1300回左右的AI得分圖表
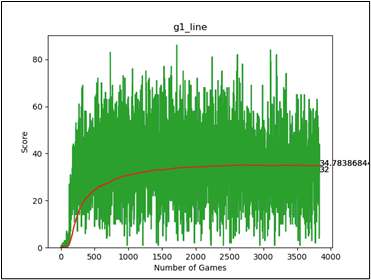
以參考資料的訓練配置來看,比較訓練250回和500回之間的平均分(紅色曲線),貪吃蛇AI在達到平均分22左右時,進步速度就不大明顯了。在經過更長時間(1300回)的訓練後,發現平均分有收斂於31左右的趨勢。推測原因是會出現身體長度過長,而將自己給圈住,導致遊戲失敗的情況。
(二)10節 / 30節身體座標配置:
由於上述失敗原因,我預期能夠透過輸入每節身體的位置,來使AI能夠知道自己的頭部不應該出現被身體圈住的情況。
在這裡的模型配置,以添加了10節身體的xy座標模型為例。因為前11個參數的大小介於01之間,這裡我也將xy座標除以遊戲視窗長寬,以確保所有參數都介於01之間。因此,這個模型的輸入有31層。
而因為輸入層的增加,有必要提升epsilon的大小以確保,AI有足夠的時間從亂數中,學習到正確的行為模式。而新的epsilon設為7*輸入層數,目的是確保所有模型的epsilon和輸入層之間是接近正比。
除此之外,我也設置了每個移動-0.01的懲罰,以避免AI在理解不能碰撞身體後,選擇不斷原地繞圈的行為。(根據訓練日誌中b~f的最終訓練成果)
圖五、10節身體位置的訓練配置
圖六、30節身體位置的訓練配置
在經過更大量的訓練回數後,觀察到訓練圖表的平均分數收斂在20以及25左右。根據對AI實際行為的觀察,可以發現AI似乎沒有理解身體位置的數據。主要原因可能為AI的主要行為模式基於參考配置的11種輸入,都是一種方向上的相對概念。同時,AI所能做出的行動(轉動蛇頭方向),也是方向相對概念的一種。因此要理解座標上的數據,相對困難。
(三)射線檢測器
基於上個訓練配置最終的推測,這次我在蛇頭放置射線檢測器,功能是延伸向四個方向,偵測是否有撞到自己的身體,以及這個距離是多長。預期的效果仍是,避免AI撞到自己的身體。
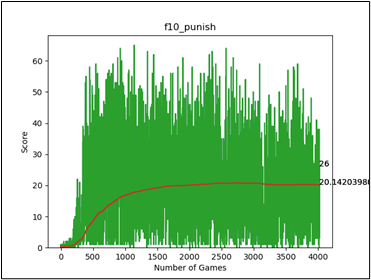
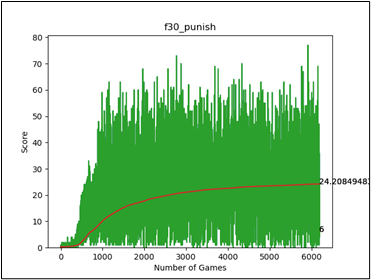
模型的輸入層增加8個,前四個代表是否偵測到身體;後四個為這個距離是多少個格子。Epsilon則依舊以正比增加。但這次不給予步數懲罰,原因是有的時候為了不把自己困住,可能會出現需要繞路的情況。(根據訓練日誌中f10, f30的訓練結果)
圖七、加入射線檢測器
最終成果上,平均分數落在35左右,說明藉由射線檢測器的加入。的確能降低蛇被自己的身體困住的部分情況。而之所以無法得到更好的效果,可能因素為,存在部分情況是四面都有自己的身體,但死路是最長的情況。(假定蛇在該環境的行為模式為,選擇最長的方向走。原因是前期訓練中最長的方向,是死路的可能性低)。
七、操作與介面說明:
在專案中,撰寫了一份使用者介面的程式,可以選擇四種不同的模式,包含:1玩家遊玩、2模型AI遊玩、3模型AI訓練、4舊模型訓練。
相比起參考資料中的專案,透過這個介面可以快速操作模型的訓練以及測試。也能夠自動儲存訓練後的模型、數據資料以及訓練圖表。並在使用舊模型進行重複訓練時,重新載入環境以及訓練過的數據。有效提高生產力。
專案下載步驟
(一) 在github上clone整個資料夾下來,打開cmd進入snack-pygame的資料夾中。
(二) 確保環境中裝有python、pytorch with cpu。以及pygame、matplotlib、numpy套件
(三) 在終端機執行userinterface.py進入操作介面
八、專案總結:
(一) 具備使用python完成AI訓練的能力
(二) 配置並使用不同的訓練資料以及參數進行訓練
(三) 了解Q_Learning算法
(四) 透過matplotlib套件,幫助訓練資料的可視化
(五) 訓練模型以及資料的儲存、載入
根據參考資料實作了AI訓練的一個小專題,理解每一行代碼的功能,並了解模型的創建,包括輸入層、隱藏層、輸出層。以及輸入資料應該如何去挑選,才能讓AI最終訓練的成果更好。並嘗試改進在參考資料中,訓練出來的AI模型會出現的問題。過程中,熟悉如何從遊戲擷取輸入資料,並載入到訓練模型。
這次的專案在最初改進時,存在一個廢案,為了降低輸入層的複雜度,透過記錄每一節身體的前一節位置來做訓練。但這種抽象資料卻會造成AI需要更大量的訓練才能明白數據的意義,後續捨棄。(根據訓練日誌中b~e的結果)
學習到關於Q_Learning算法中,如何計算新的Q值,並利用該值,來實現agent的操作。包含折扣率對於AI的影響、隨機行動的必要等等。
了解了如何去利用matplot,來幫助繪製AI訓練時的資料圖,以幫助分析AI訓練的獎勵值變化。而為了處理舊模型訓練的問題,也實現了關於資料之間的型態轉換、讀檔、存檔的功能。以方便後續訓練中,保證訓練資料的連續、訓練圖表的完整性。
九、未來規劃:
(一) 嘗試不同以及更龐大的輸入資料,了解輸入資料和貪吃蛇AI成效之間的差異。並訓練出效果更好的貪吃蛇
(二) 學習deep q learning用於改進AI訓練的成果
(三) 學習生成對抗網路,並應用在此次專案中,訓練AI之間的競爭,以了解該種神經網路的實作。
十、參考資料:
Teach AI To Play Snake - Reinforcement Learning Tutorial With PyTorch And Pygame, from https://youtu.be/5Vy5Dxu7vDs
pygame官方文檔,取自 https://www.pygame.org/docs/tut/PygameIntro.html
机器学习9:关于pytorch中的zero_grad()函數,取自 https://blog.csdn.net/weixin_39504171/article/details/103179067
PyTorch使用GPU训练的两种方法实例,取自 https://www.jb51.net/article/248324.htm
PyTorch的nn.Linear()详解,取自 https://blog.csdn.net/qq_42079689/article/details/102873766
【Day 23】 Google ML - Lesson 9 - 加速ML模型訓練的兩大方法(如何設定batch/檢查loss頻率)、batch size, iteration, epoch的概念和比較,取自 https://ithelp.ithome.com.tw/articles/10219945
30 天在 Colab 嘗試的 30 個影像分類訓練實驗,取自 https://ithelp.ithome.com.tw/users/20107299/ironman/4809
并行化强化学习 —— 初探 —— 并行reinforce算法的尝试 (上篇:强化学习在多仿真环境下单步交互并行化设计的可行性),取自 https://www.cnblogs.com/devilmaycry812839668/p/14221576.html
手把手教你做一个强化学习的环境,用pygame搭建一个可视化训练游戏环境(一),取自 https://blog.csdn.net/weixin_48174100/article/details/119242038