Compiler CH3 Scanning
Compiler CH3 Scanning
scanner(lexical analyzer)
- the interface between source & compiler
- routine called by passer
Tokens
- Although the task of the scanner is to convert the entire source program into a sequence of tokens, the scanner will rarely do this all at once.
- Instead, the scanner will operate under the control of the parser, returning the single next token from the input on demand via a function that will have a declaration similar to the C declaration
- TokenType getToken(void);
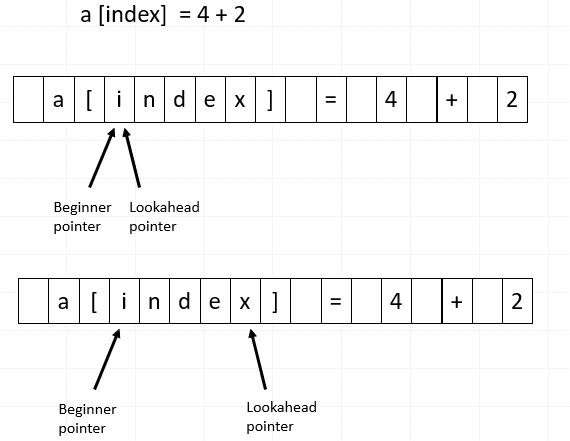
Input Buffering
用於lookahead
- 兩個pointer
- 一個用於紀錄開始
- 一個用於lookahead
Regular Expression
Regular expr. vs. finite Automata
Regular Expression: A notation suitable for describing tokens
Regular Expr. can be converted into finite automata
Finite Automata: Formal specifications of transition diagrams
Operations of string(I)
Length
- e.g., |0| = 1, |x| = the total number of symbols in string x, empty string denoted 𝜀, |𝜀|=0 (note: {𝜀}≠∅)
Concatenation
- e.g., 𝑥.𝑦=𝑥𝑦, 𝜀𝑥=𝑥, 𝑥𝜀=𝑥,
, ,
Prefix - any # of leading symbols at the string
proper prefix (shown below)
Operations of string(II)
Suffix - any # of trailing symbols at the string
proper suffix (explained below)
Substring - any string obtained by deleting a prefix and a suffix.
proper substring (explained below)
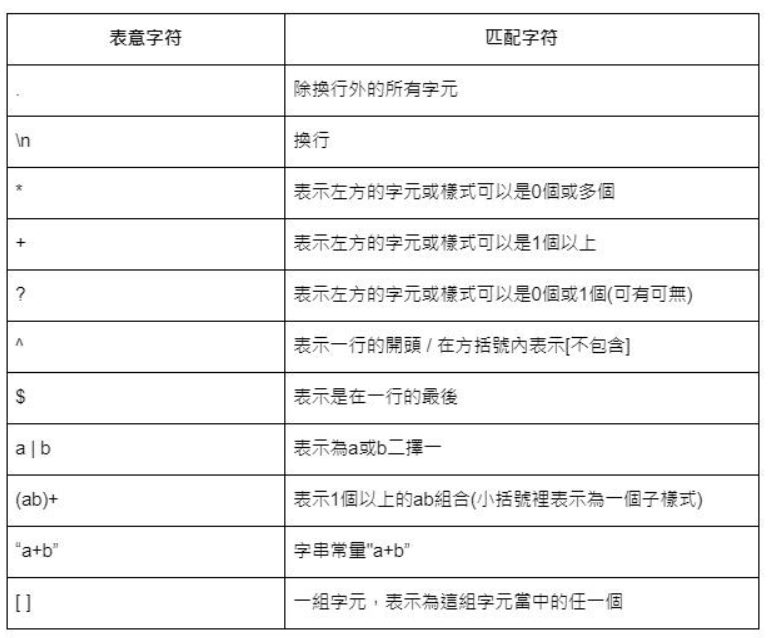
Rules for constructing regular expressions
∅ is a regular expression denoting { }. i.e., 𝐿(∅)={ }
𝜺 is a regular expression denoting {𝜀}, the language containing only empty string 𝜀. 𝐿(𝜺)={𝜀}
For each 𝑎 in Σ, 𝒂 is a regular expression denoting {𝑎}, a single string a. i.e., 𝐿(𝒂)={𝑎}
If 𝑅 and 𝑆 are regular expressions then
are regular expressions denoting union, concatenation, cleen closure of 𝑅 and 𝑆.
Rules
- 𝑅|𝑆=𝑆|𝑅
- 𝑅|(𝑆|𝑇)=(𝑅|𝑆)|𝑇
- 𝑅(𝑆|𝑇)=𝑅𝑆|𝑅𝑇, (𝑆|𝑇)𝑅 = 𝑆𝑅|𝑇𝑅
- 𝑅(𝑆𝑇)=(𝑅𝑆)𝑇
- 𝜀𝑅=𝑅𝜀=𝑅
- Precedence: ( ), ∗, ∙ , |
- ?是結束
Finite Automata(Finite state machine)
- Depict FA as a directed graph
- each vertex corresponds to a state
- there is an edge from the vertex corresponding to state
to vertex corresponding to state iff the FA has a transition from state to on input 𝜎. - i.e.,

- The language defined by an F. A. (Finite Automata) is the set of input string it accepts.
- regular expression –> non-deterministic F. A. –> deterministic F. A. –> regular expression
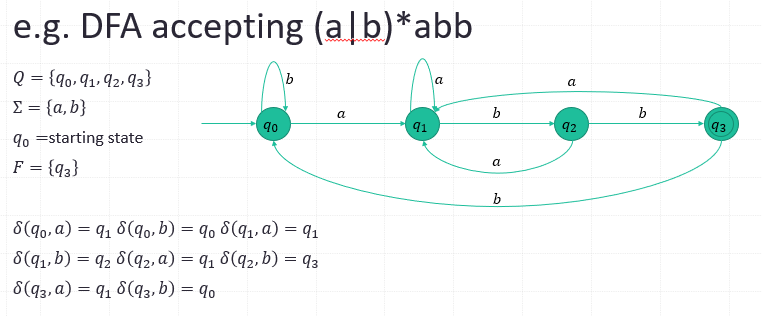
Deterministic finite automata(DFA)
- It has no transition on input 𝜀
- For each state s and input symbol a, there is at most one edge labeled a leaving 𝒔.
- 𝑀=(𝑄, Σ, 𝛿, 𝑞_0, 𝐹), where
- 𝑄 = a finite set of states
- Σ = a set of finite characters
- 𝛿= transition function 𝛿:𝑄×Σ→𝑄
- 𝑞_0 = starting state
- 𝐹 = a set of accepting states (a subset of 𝑄 i.e. 𝐹⊆𝑄)
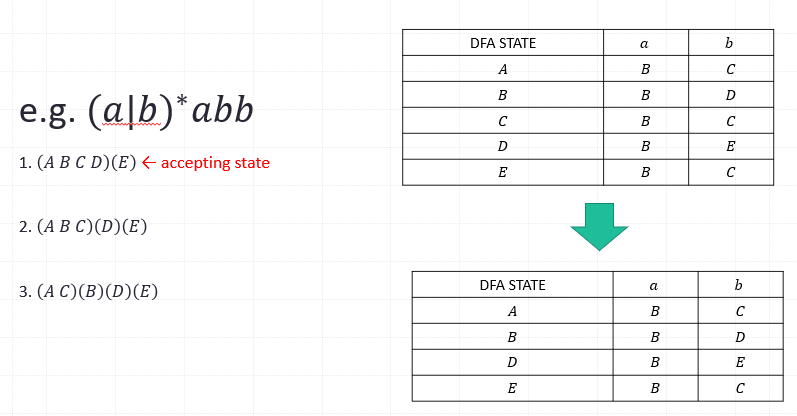
Ex.
- (a|b)*abb
Non-deterministic Finite Automata
𝑀′=(𝑄′, Σ, 𝛿′, 𝑞_0, 𝐹), where
- 𝑄′ = a finite set of states
- Σ = a set of finite characters
- 𝛿′= transition function 𝛿′:𝑄′×(Σ∪𝜀)→
where means it can map to multiple states - 𝑞_0 = starting state
- 𝐹 = a set of accepting states (a subset of 𝑄′ i.e. 𝐹⊆𝑄′)
Given a string 𝑥 belonging to
if there exists a path in a NFA 𝑀’ s.t. 𝑀’ is in a final state after reading 𝑥, then 𝑥 is accepted by 𝑀’. i.e., if 𝛿′( , 𝑥)=𝛼⊆𝑄′ and 𝛼∩𝐹≠∅ then 𝑥 belongs to 𝐿(𝑀’).
Ex.
- (a|b)*abb

Theorem
The followings are equivalent:
- regular expression
- NFA
- DFA
- regular language
- regular grammar
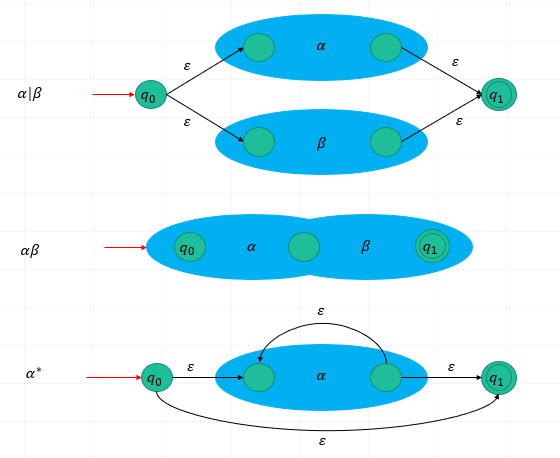
Algorithm: constructing an NFA from a regular expr.
- For 𝜀 we construct the NFA ==>
- For 𝑎 in Σ we construct the NFA ==>
- Proceed to combine them in ways that correspond to the way compound regular expressions are formed, i.e., transition diagram for 𝛼, 𝛽.
- 𝛼|𝛽
- 𝛼𝛽
Ex.
Construct the r.e. 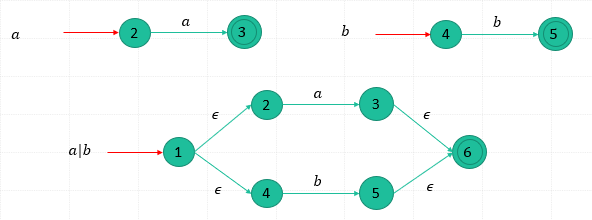
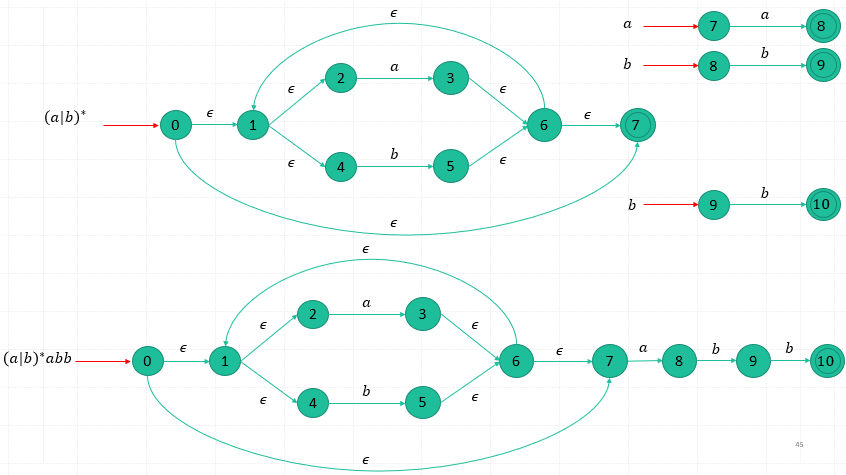
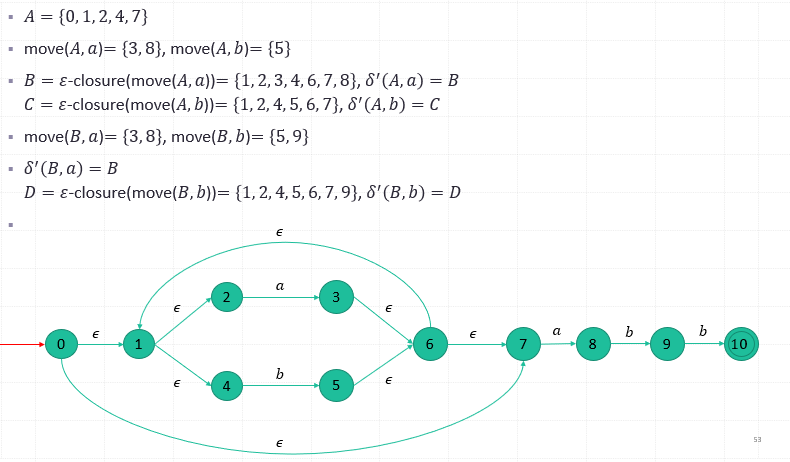
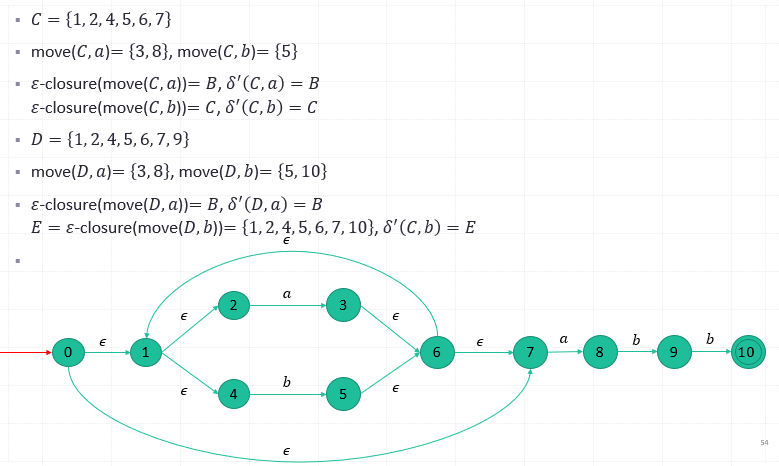
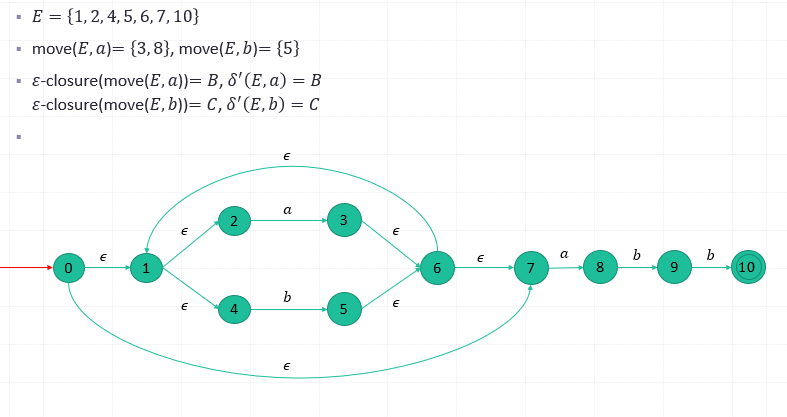
How to construct a DFA based on an equivalent NFA?
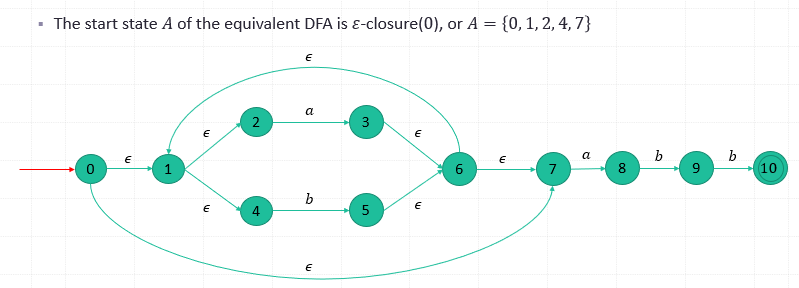
- Each state of the DFA is a set of states which the NFA could be in after reading some sequence of input symbols.
- The initial state of the DFA is the set consisting of 0, the initial state of NFA, together with all states of NFA that can be reached from 0 by means of 𝜀-transition.
𝜀-closure(𝑠)
Def. The set of states that can be reached from 𝑠 on 𝜀-transition alone.
Method:
- 𝑠 is added to 𝜀-closure(𝑠).
- if 𝑡 is in 𝜀-closure(𝑠), and there is an edge labeled 𝜀 from 𝑡 to 𝑢 then 𝑢 is added to 𝜀-closure(𝑠) if 𝑢 is not already there.
𝜀-closure(𝑇) : The union over all states 𝑠 in 𝑇 of 𝜀-closure(𝑠). (Note: 𝑇 is a set of states)
move(𝑇, 𝑎): a set of NFA states to which there is a transition on input symbol 𝑎 from some state 𝑠 in 𝑇.
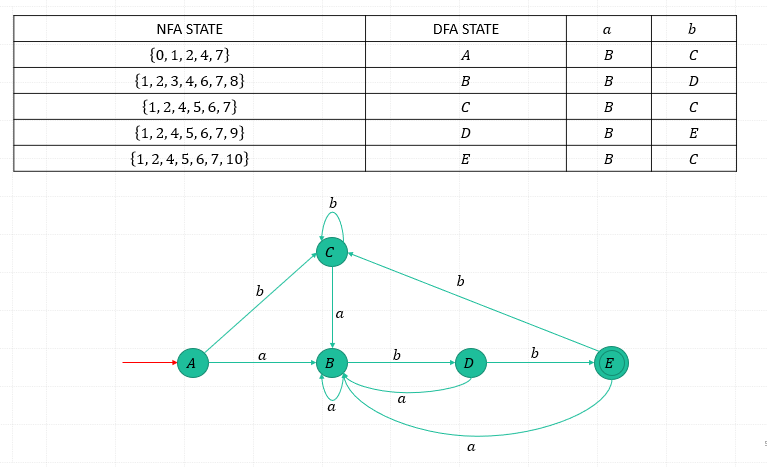
Algorithms
- Computation of 𝜀-closure
- The subset construction
- Given a NFA 𝑀=(𝑄, Σ, 𝛿, 𝑞_0, 𝐹), construct a corresponding DFA 𝑀′=(𝑄′, Σ, 𝛿′, 𝑞_0, 𝐹′)
- (1) Compute the 𝜀-closure(𝑠), 𝑠 is the start state of 𝑀. Let it be 𝑆. 𝑆 is the start state of 𝑀’ and 𝑄^′={𝑆}
- (2) …..
- (3) 𝐹^′={𝑞′∈𝑄^′ |𝑞′∩𝐹≠∅}
Ex.
minimizing the number of states of DFA
- Principle: only the states in a subset of NFA that have a non-𝜀-transition determine the DFA state to which it goes on input symbol.
- Two subsets can be identified as one state of the DFA, provided:
- they have the same non-𝜀-transition-only states
- they either both include or both exclude accepting states of the NFA
algorithm
- Two states are distinguished if there exists a string which leads to final states and non-final states when it is fed to the two states.
- Find all groups of states that can be distinguished by some input string.
- Construct a partition and repeat the algorithm of getting a new partition.
- Pick a representative for each group.
- Delete a dead state and states unreachable from the initial state. Make the transition to the dead states undefined.
ex.
- (a|b)*abb