Computer Network CH3 Transport Layer
Computer Network CH3 Transport Layer
Transport Layer: Overview
Goal
- understanding principle of transport layer servics
- multiplexing, demultiplexing
- reliable data transfer
- flow control
- congestion control
- learn about internet transport layer protocols
- UDP
- TCP
- TCP congestion control
Transport-Layer services
Transport services and protocols
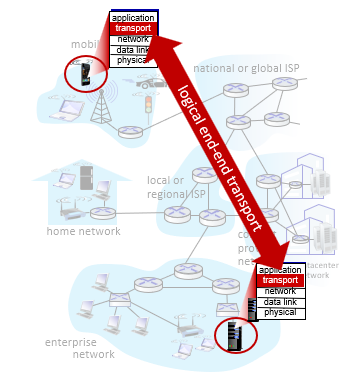
- provide logical communication between application processes running on different hosts
- transport protocols actions in end systems:
- sender: application messages into segments, passes to network layer
- receiver: reassembles segments into messages, passes to application layer
Transport vs. network layer services and protocols
transport layer:
- communication between processes
- relies on, enhances, network layer services
- process與process之間的溝通
network layer:
- communication between hosts
- host與host之間的溝通

Actions
Sender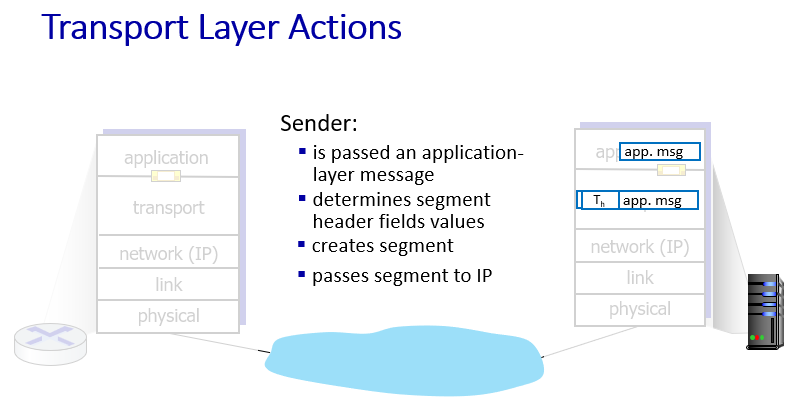
Receiver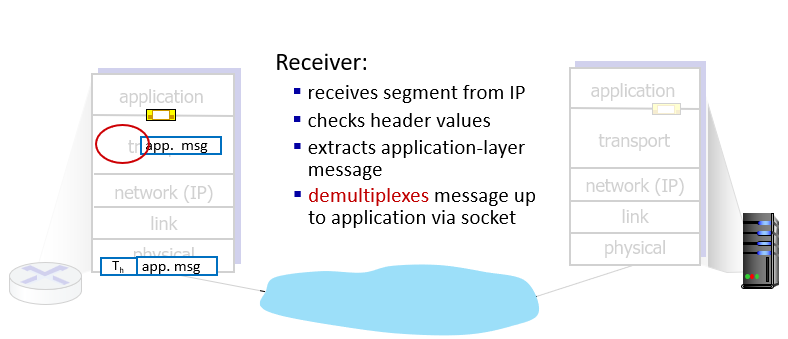
Two principal Internet transport protocols
TCP: Transmission Control Protocol
- reliable, in-order delivery
- congestion control
- flow control
- connection setup
UDP: User Datagram Protocol
- unreliable, unordered delivery
- no-frills extension of “best-effort” IP
services not available:
- delay guarantees
- bandwidth guarantees
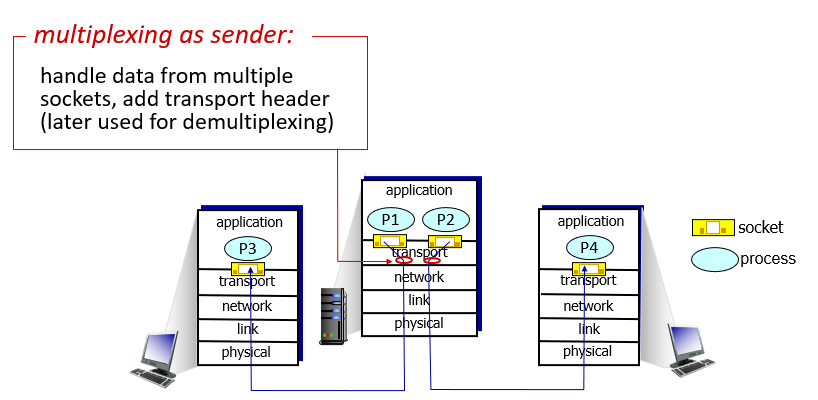
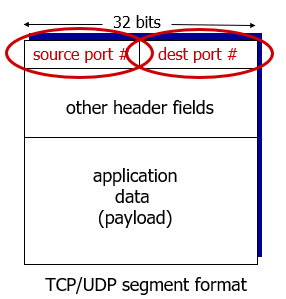
Multiplexing and demultiplexing
sender

reciver
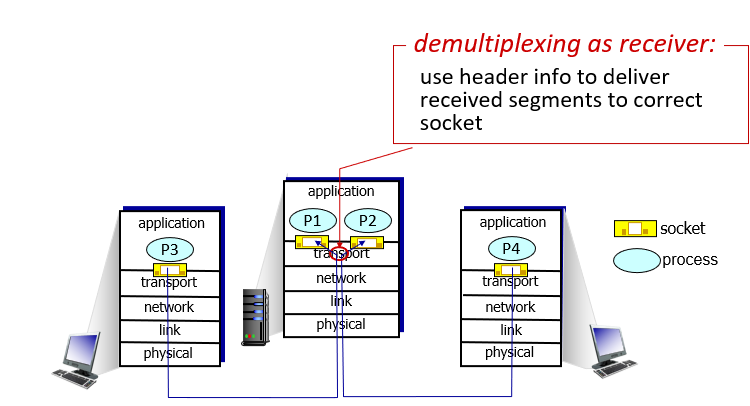

How demultiplexing works
host receives IP datagrams
- each datagram has source IP address, destination IP address
- each datagram carries one transport-layer segment
each segment has source, destination port number
- host uses IP addresses & port numbers to direct segment to appropriate socket
host uses IP addresses & port numbers to direct segment to appropriate socket
- 使用IP address和port numbers
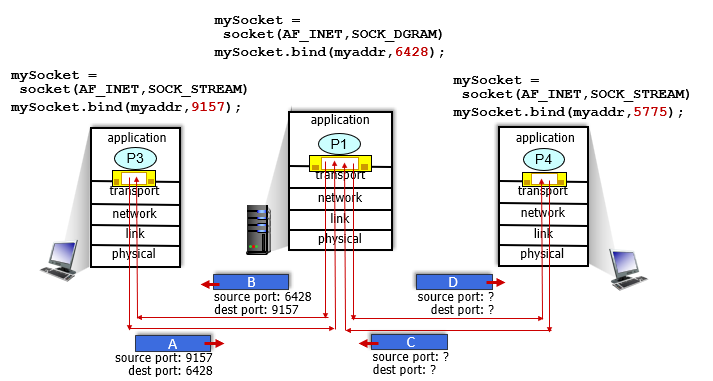
Connectionless demultiplexing
Recall:
- when creating socket, must specify host-local port #:
DatagramSocket mySocket1 = new DatagramSocket(12534);
when creating datagram to send into UDP socket, must specify
- destination IP address
- destination port #
when receiving host receives UDP segment:
- checks destination port # in segment
- directs UDP segment to socket with that port #
只要目標port numbers一樣,不同來源的datagrams也會被送到同樣的socket
Connection-oriented demultiplexing
TCP socket identified by 4-tuple:
- source IP address
- source port number
- dest IP address
- dest port number
demux: receiver uses all four values (4-tuple) to direct segment to appropriate socket
server may support many simultaneous TCP sockets:
- each socket identified by its own 4-tuple
- each socket associated with a different connecting client
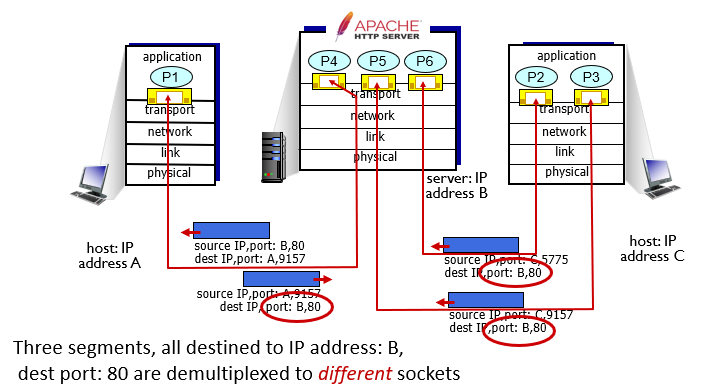
- 不只是看des port, 考慮整個4-tuple的內容
Summary
- Multiplexing, demultiplexing: based on segment, datagram header field values
- UDP: demultiplexing using destination port number (only)
- TCP: demultiplexing using 4-tuple
- source and destination IP addresses
- … port numbers
- Multiplexing/demultiplexing happen at all layers
Connectionless transport: UDP
UDP
- “no frills,” “bare bones” Internet transport protocol
- “best effort” service, UDP segments may be:
- lost
- delivered out-of-order to app
- connectionless:
- no handshaking between UDP sender, receiver
- each UDP segment handled independently of others

UDP use:
- streaming multimedia apps (loss tolerant, rate sensitive)
- DNS
- SNMP
- HTTP/3
RFC 768
if reliable transfer needed over UDP (e.g., HTTP/3):
- add needed reliability at application layer
- add congestion control at application layer
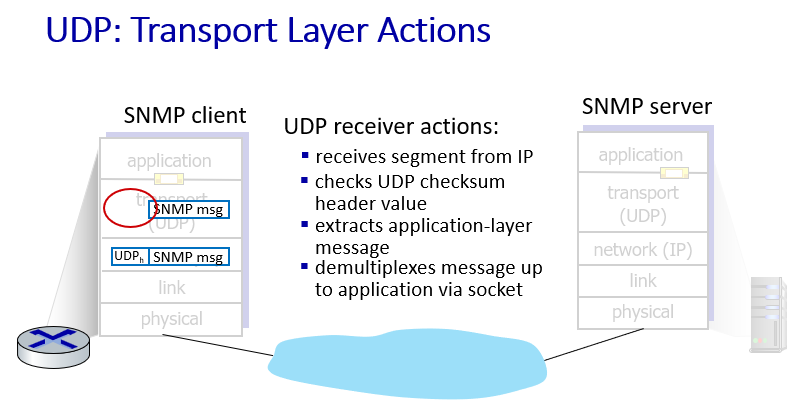
Actions
Sender
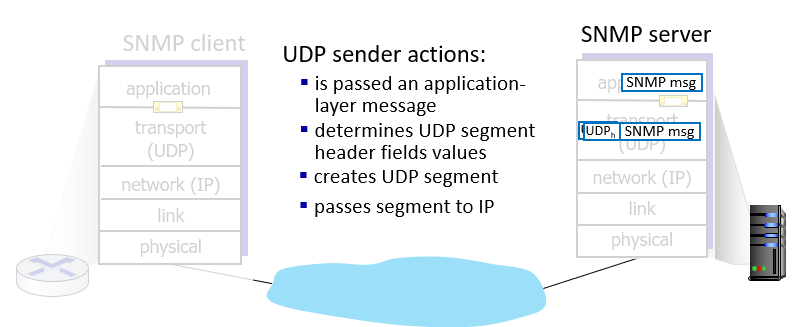
receiver
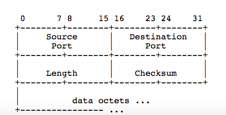
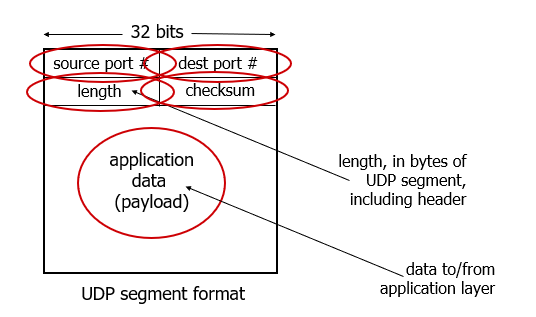
UDP segment header
Checksum
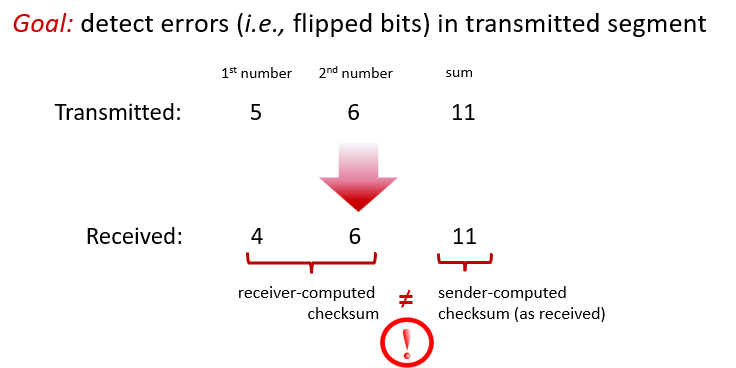
Internet checksum
sender:
- treat contents of UDP segment (including UDP header fields and IP addresses) as sequence of 16-bit integers
- checksum: addition (one’s complement sum) of segment content
- checksum value put into UDP checksum field
receiver:
- compute checksum of received segment
- check if computed checksum equals checksum field value:
- not equal - error detected
- equal - no error detected.
- But maybe errors nonetheless? More later ….
Ex.
檢查的例子

仍有可能發生錯誤

Summary
“no frills” protocol:
- segments may be lost, delivered out of order
- best effort service: “send and hope for the best”
UDP has its plusses:
- no setup/handshaking needed (no RTT incurred)
- can function when network service is compromised
- helps with reliability (checksum)
build additional functionality on top of UDP in application layer (e.g., HTTP/3)
Principles of reliable data transfer(RDT)
Principles of reliable data transfer
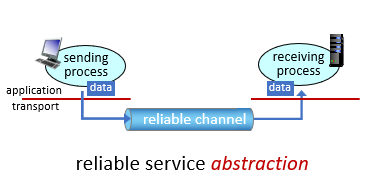
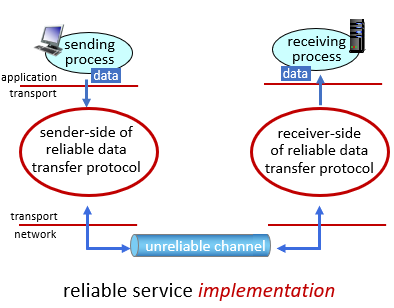
- 網路通道不能確定是否信賴
使用可信賴的protocal
- 複雜度取決於使用的unreliable channel
傳送端與接收端不知道彼此的狀態
- 除非接收端回覆
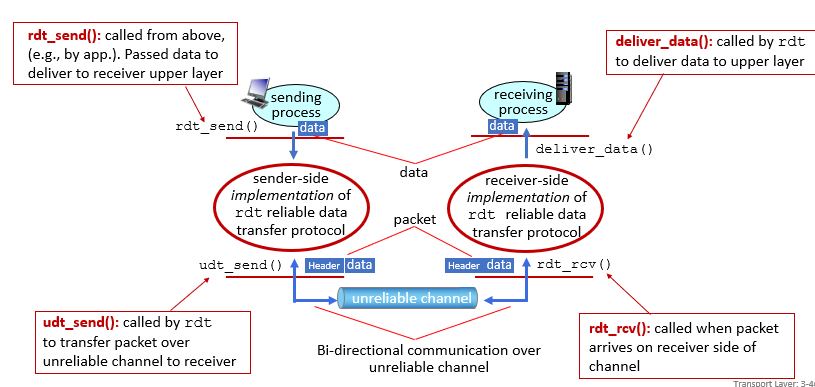
protocol interface
sender:
- application layer呼叫rdt_send
- transport layer呼叫udt_send
- 將packet經過unreliable的通道給receiver

receiver:
- 封包進來呼叫rdt_rcv
- rdt_rcv呼叫deliver_data
雙向頻道
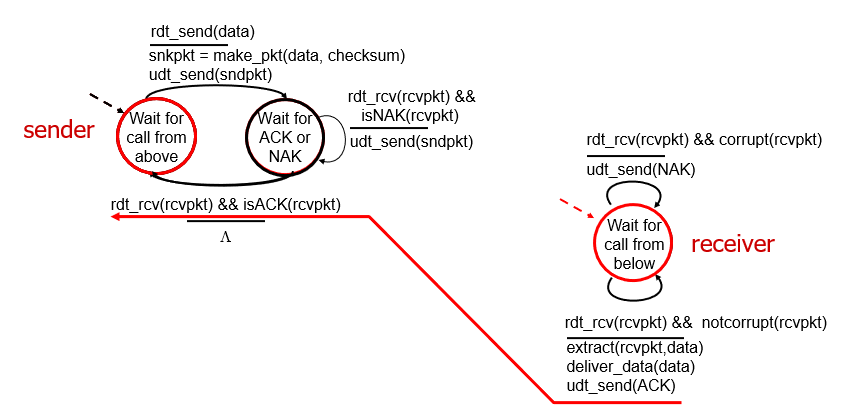
Reliable data transfer: getting started
- 了解版本差異
- 為什麼要發展下一個版本
using FSM(finite state machine)
- 上面是event
- 下面是action
rdt1.0: reliable transfer over a reliable channel(不考)
進行在underlying channel(正在進行的)
underlying channel perfectly reliable
- no bit errors
- no loss of packet
receiver wait for call from below(等待封包傳送到)

rdt2.0: channel with bit errors
存在bit error
- using checksum to detect bit error
如何recover error?
- receiver 回覆
- acknowledgements (ACKs) 接收端回覆是否收到封包
- NAKs 接收端回覆收到了,但訊息怪怪的
- receiver explicitly tells sender that pkt had errors
- 如果傳送端接收到NAKs -> 重送
- 不管是什麼問題
- 第二次以上傳送封包
- 上述過程稱之為stop and wait
FSM
- 2.0的特色要加入checksum
- sender 多一個狀態 wait for ACK or NAK
因為需要通過ACK, NAK來了解接收端的狀態
- 故需要protocol
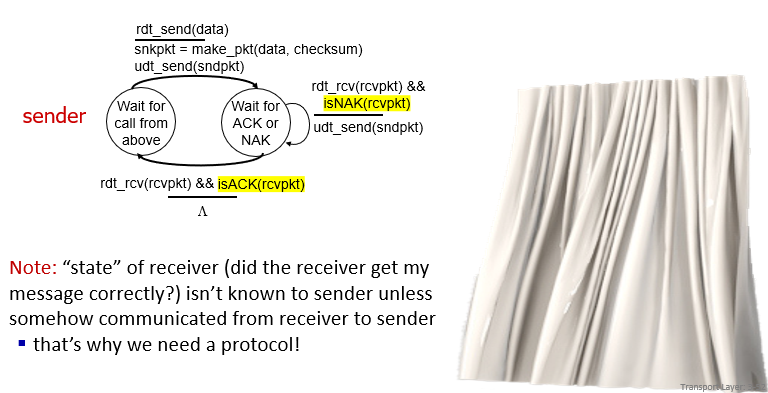
has a fatal error
- 如果ACK, NAK也是corrupt?
- 不能就一直重傳
- 可能造成duplicate
handling duplicate
- sender add sequence number to each pkt
- 收到重複就拋棄
- 即rdt2.1
rdt2.1: sender, handling garbled ACK/NAKs
sender多傳送一個sequence number
- 讓receiver知道這是pkt 0
sender
- 如果corrupt or NAK不斷重傳
- 直到not corrupt and ACK
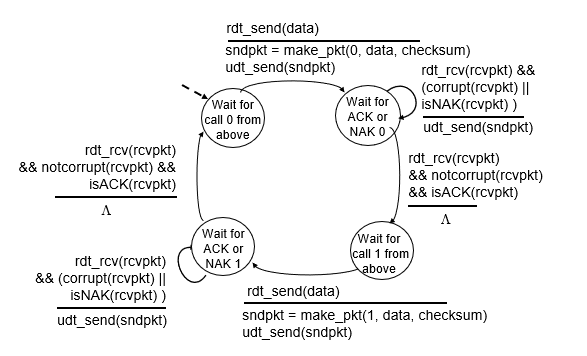
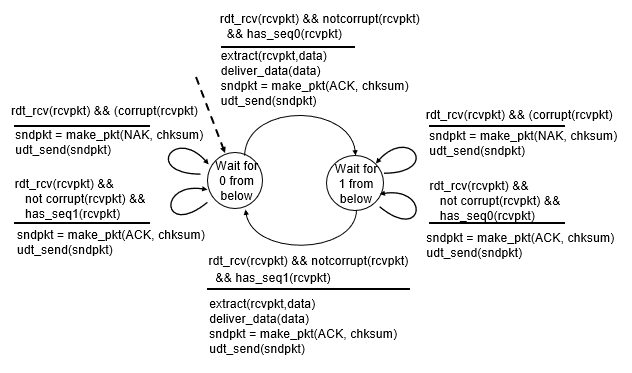
receiver
- sndpkt包含ACK和checksum(2.0也有)
- ACK中會有sequence number
- 回傳給sender
discussion
- sender
- seq # added to pkt
- 0, 1 is enough, if stop and wait
- pipeline 就不行
- 必須記錄0, 1
- receiver
- check if duplicate
- can not known its last ACK/NAK received OK at sender
- thus 2.2 created
rdt2.2: a NAK-free protocol
using ACK only
must explictly include seq # of pkt being ACKed
duplicate ACK at sender = NAKs
- retransmit
receiver
- sequence # 放進ACK
- 回傳ACK, checksum
As we will see, TCP uses this approach to be NAK-free
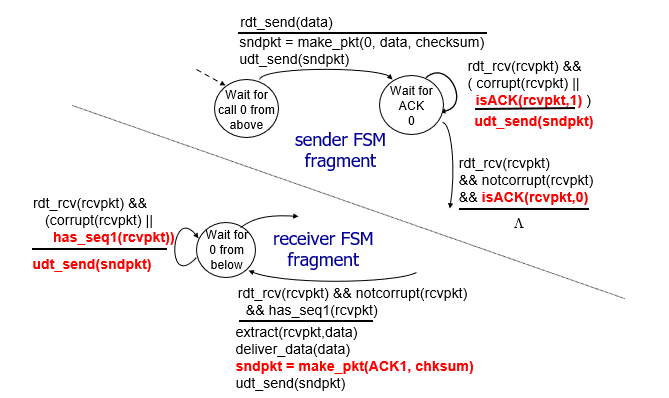
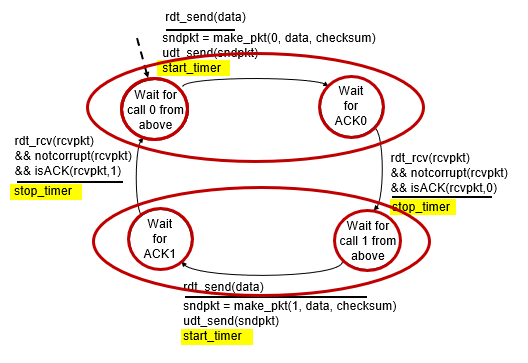
rdt3.0: channels with errors and loss
new channel assumption
- lose packet(data, ACKs)
- previous skill, but not enough
- loss就什麼都收不到了
Approach
- add timer
- sender waits “reasonable” amount of time for ACK
- retransmit if no ACK
- if pkt just delay?(just on the way)
- duplicate is solved by seq #
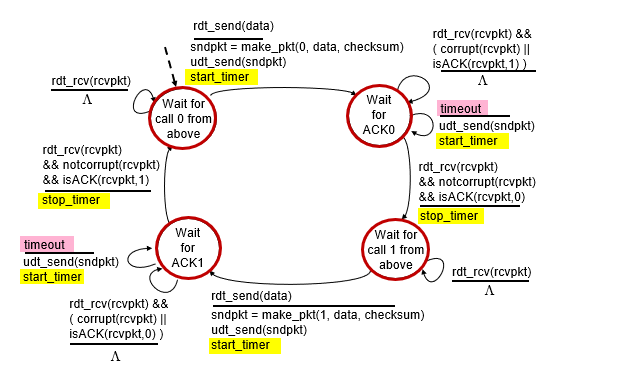
多了一個計時器
- 如果ACK的seq # 不對,就不做事直到timeout
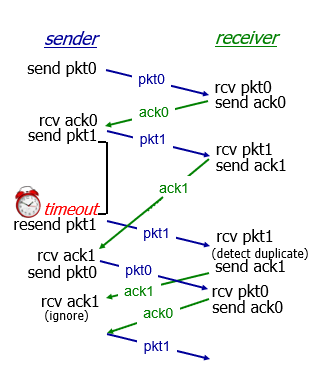
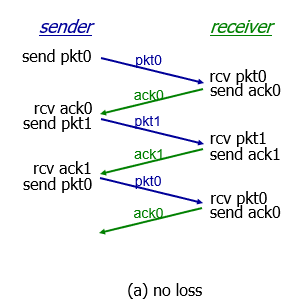
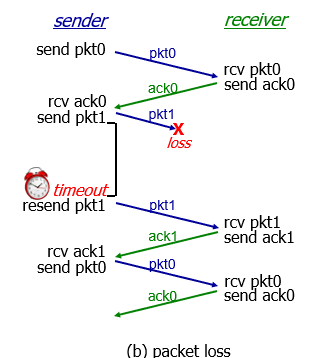
In action
- no loss
- packet loss
- ACK loss
- after sender resent, receiver detect duplicate
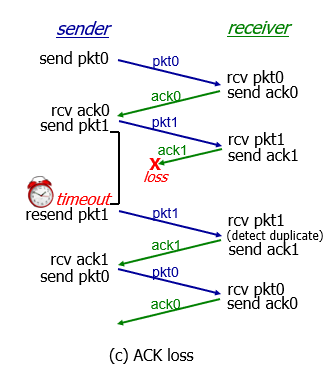
- premature timeout/delayed ACK(太早)
- receive ACK the same -> ignore
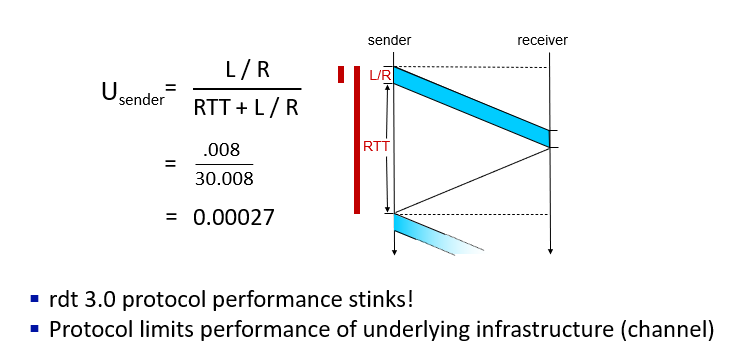
performance

operation
- blue part is
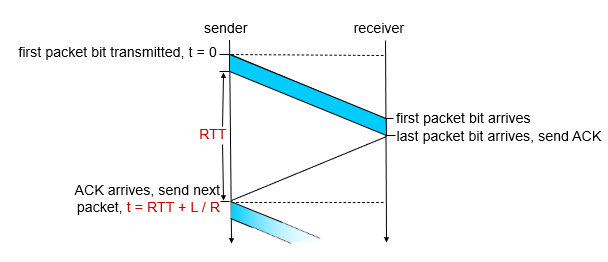
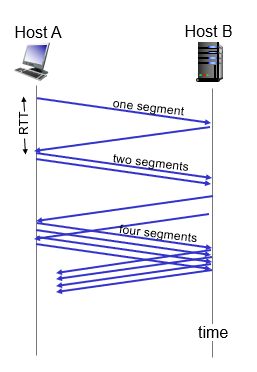
using many time to sent little bit data, caused big RTT
is too small
using pipeline!
sender allows multiple, “in-flight”, yet-to-be-acknowledge pkt
- range of seq # must be increased
- buffering at sender and/or receiver
increased utilization(看過就好)

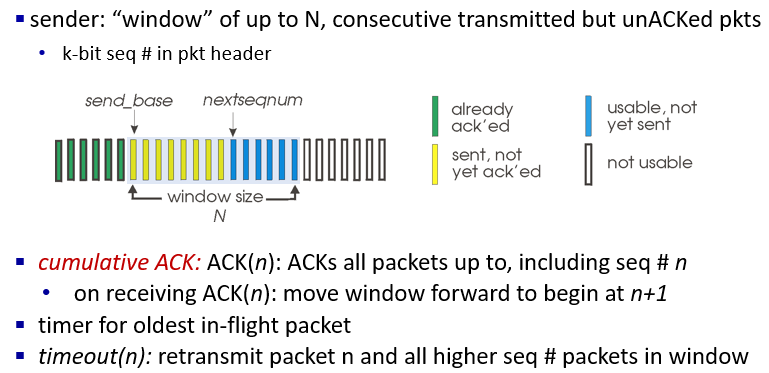
Go-Back-N: sender
Sender
- sender window of up to N, consecuive transmitted but unACKed pkts
- k-bit seq # in pkt header
- sender base
- cumulative ACK:一次回應多個ACK
- timer從最早的pkt開始算
- 如果沒收到,回到最前面的重傳
Reciver
- 回傳ACK根據最高的seq # in order
- only remember rcv_base
- may duplicate ACKs
- out-of-order pkt
- can discard or buffer
- re-ACK pkt with highest in-order seq #

in action
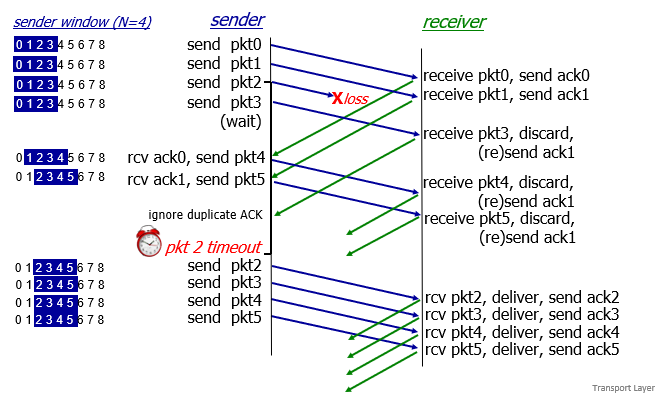
- 太蠢了,因為一個loss重傳一大堆
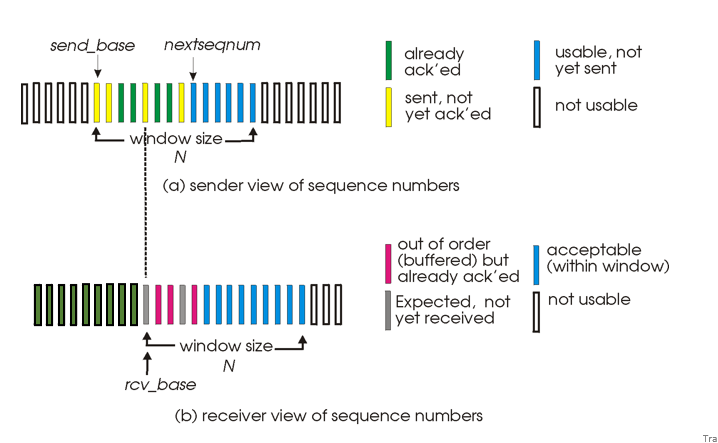
Selective repeat
維持timer for specific pkt
- 重傳time out的那個
sender
reciver
- 多了一個expected, not yet recived
p3.77看過就好

in action
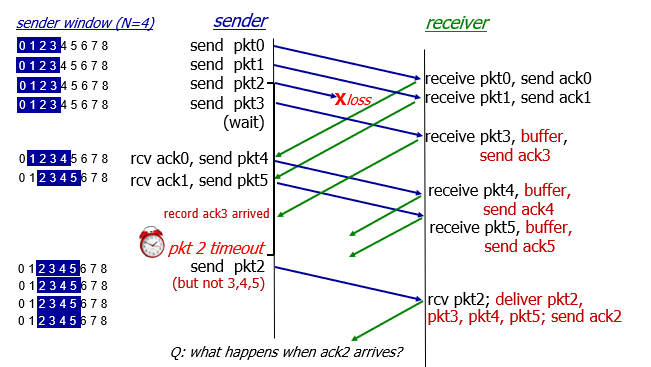
- 不連續的pkt會被buffer,等到補齊後一次deliver上去
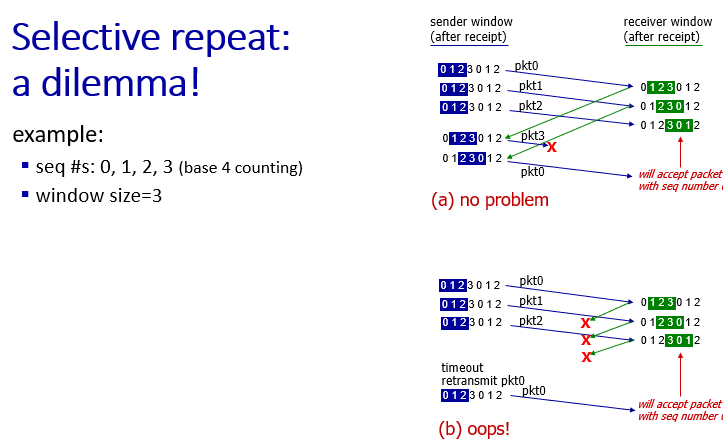
dilemma!
- if seq # is too close to window size
Connection-oriented transport: TCP
overview
point-to-point:
- one sender, one receiver
reliable, in-order byte steam:
- no “message boundaries”
full duplex data:
- bi-directional data flow in same connection
- MSS: maximum segment size
cumulative ACKs
pipelining:
- TCP congestion and flow control set window size
connection-oriented:
- handshaking (exchange of control messages) initializes sender, receiver state before data exchange
flow controlled:
- sender will not overwhelm receiver
TCP segment structure
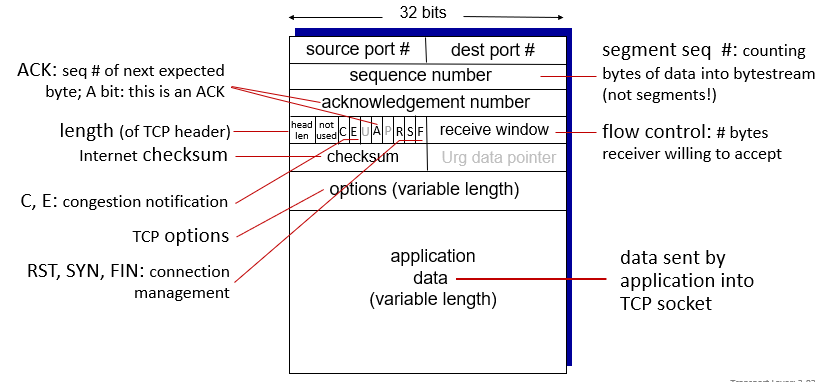
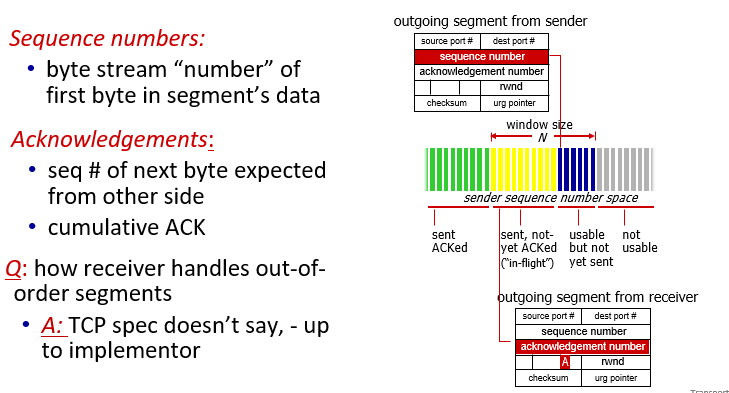
sequence numbers, ACKs
Ex.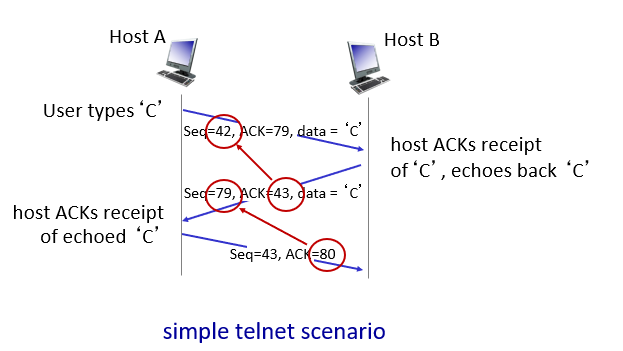
Round trip time, timeout
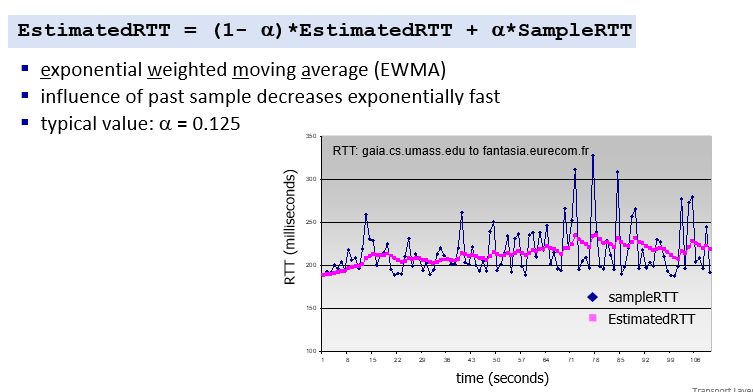
estimate RTT
- 下面那個SampleRTT應該是estimateRTT

EWMA
- 過去的RTT影響會指數遞減
Real timeout interval
- 會用estimateRTT + safety margin

TCP Sender
event: data received from application
- create segment with seq #
- seq # is byte-stream number of first data byte in segment
- start timer if not already running
- think of timer as for oldest unACKed segment
- expiration interval: TimeOutInterval
event: timeout
- retransmit segment that caused timeout
- restart timer
event: ACK received
- if ACK acknowledges previously unACKed segments
- update what is known to be ACKed
- start timer if there are still unACKed segments
Receiver ACK Generation
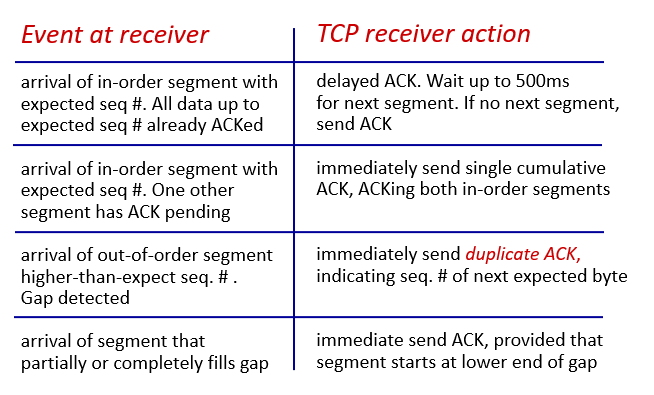
retransmission scenarios
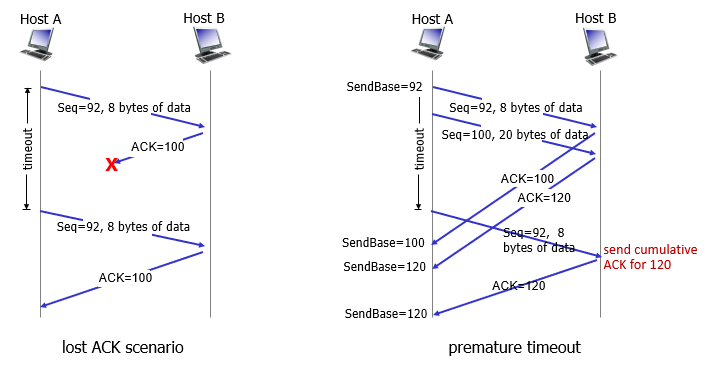
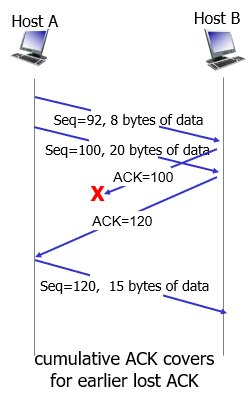
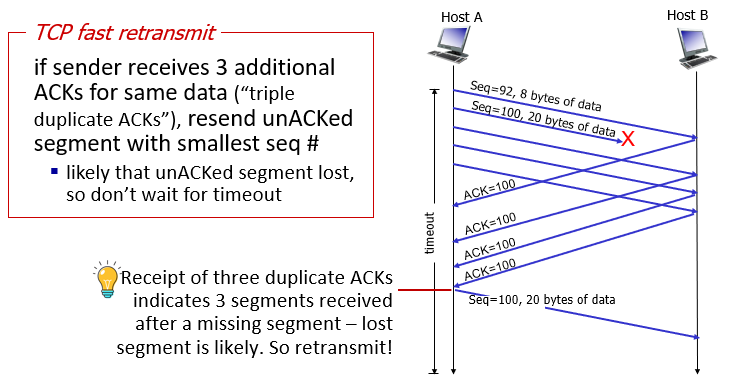
- fast
TCP flow control
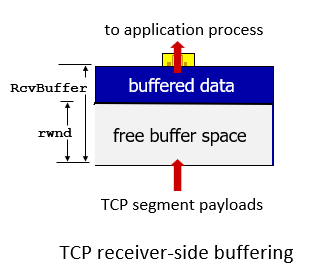
receiver 告訴sender 他已經不能再接收了
- 希望best effort,傳送端盡量傳,交給接收端控制
network layer會一直把資料傳輸上去
- TCP 會把資料丟給application layer
- application layer拆資料
- 如果拆得比傳輸得慢? 如下
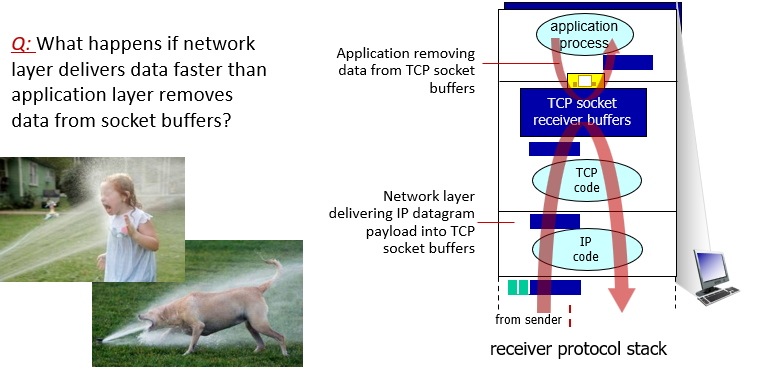
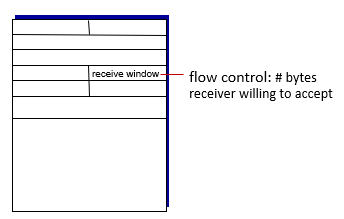
rcv window
- 接收端使用free buffer在window的大小,告訴sender不要傳超過
- 放在header中

TCP connection management
TCP會做handshake(三項交握)
- 目的是建立連線tcp connection
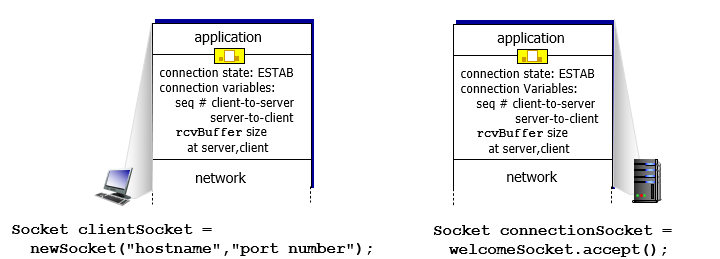
header中包含
- receiver Seq #
- rcvBuffer size
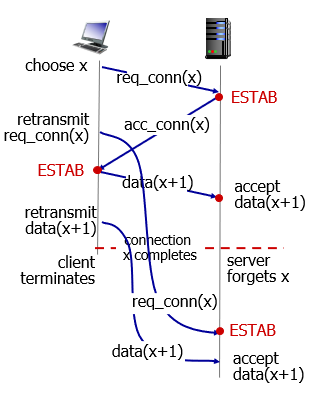
2-way handshake:
- 沒有發生問題都ok
- 如果timeout
- sender不知道acc_conn是第一個還是第二個req_conn的回覆
- 導致half connection,如圖
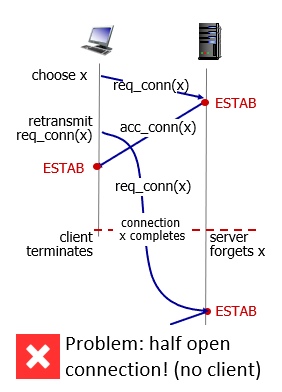
- server以為client又開啟了一次
- 但client只是重傳
- 甚至造成duplicate data被accepted
3-way handshake:
- client送了一個TCP SYN msg
- server回傳SYN ACK
- client回傳ACK(for SYN ACK)
- client知道server存活,所以這個ACK可以帶資料
- 雙方都會初始化一個seq #
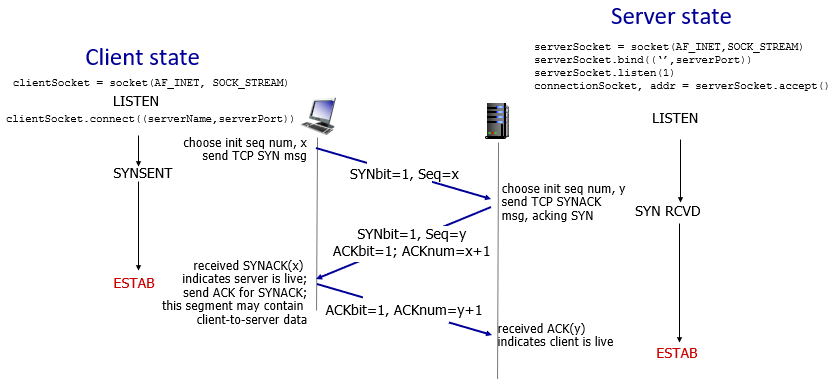
- 因為是ACK對方的ACKbit,所以回傳ACKnum = x+1(多1bit)

closing TCP connection(沒什麼特別的)
- send FIN bit = 1
- 雙方同時關閉
TEST:為什麼不做雙向交握?
雙向交握在沒發生問題的時候都ok,
但如果sever回傳的acc_conn timeout了。
sender會再次retransmit,之後sender就不知道那個acc conn是回應哪一個rec_conn,
導致half connection(no client)。
Principe of congestion control
congestion
- too many senders: sending too fast
- caused long delay(queueing in router buffers)

flow control
- one sender: sneding too fast

delay很難解決,比起through put
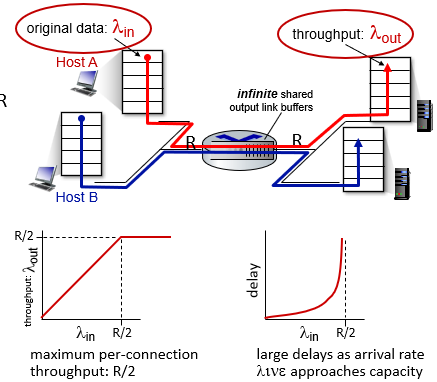
scenario 1 p3.111
infinite buffer
- 所有資料都可以暫存在router
- 只會造成delay increasing, no loss
沒有需要被重傳的pkt
scenario 2(會考) p3.112
finite buffer
- pkt drop or timeout
- transport layer 資料需要重傳,
- application layer的
一樣
- transport layer 資料需要重傳,
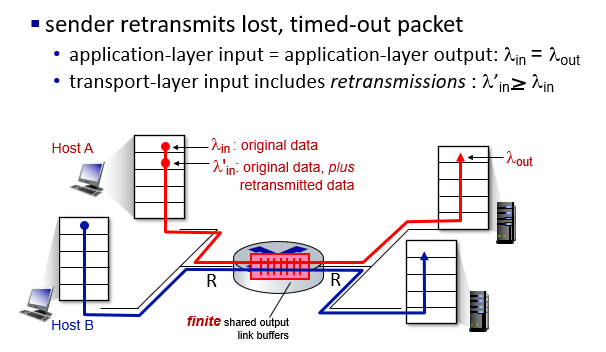
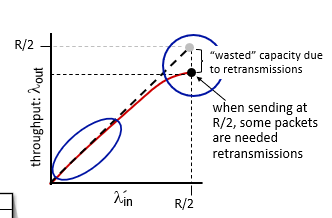
through put不能提升到上限(
- 因為檔案可能需要重傳caused by loss or timeout
- 存在duplicate(不必要的重傳)
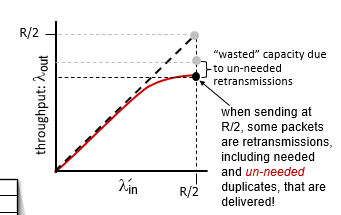
cost

sceneario 3 p3.118
4 senders
multi-hop paths
- 經過兩顆以上的router(兩個節點中的一個邊叫做one hot)
先傳入的data(紅色)占滿了router(12點方向)的buffer
則藍色遇到bottle neck
- 藍色的data在該router被丟掉了
- 藍色的
增加,但 沒有增加多少 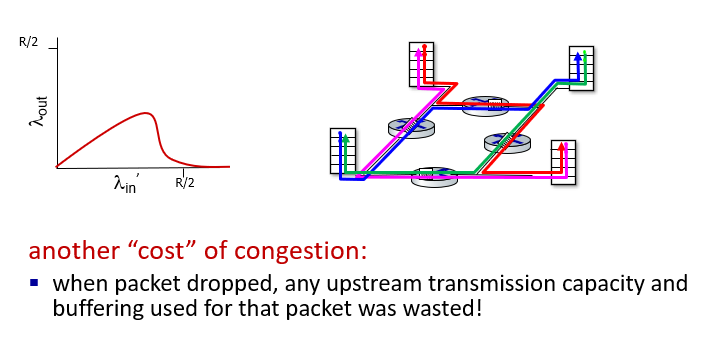
總結 p3.120
- un-needed duplicates是因為time out
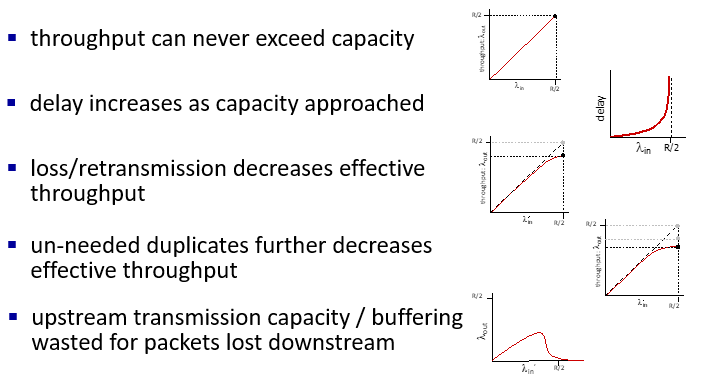
Approaches
end-end congestion control(TCP using)
- 不知道網路中發生甚麼
- time out就重傳
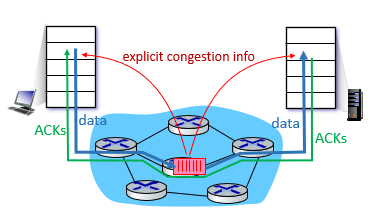
network-assisted congestion control
- router通知hosts
- may indicate congestion level or explicitly set sending rate
TCP congestion control
TCP congestion control AIMD p3.124
網路還沒壅塞,盡可能增加傳輸效率
一次增加一個maximum seg size
逐步增加直到loss detect再降低
- 倍數降低multiplicative decrease
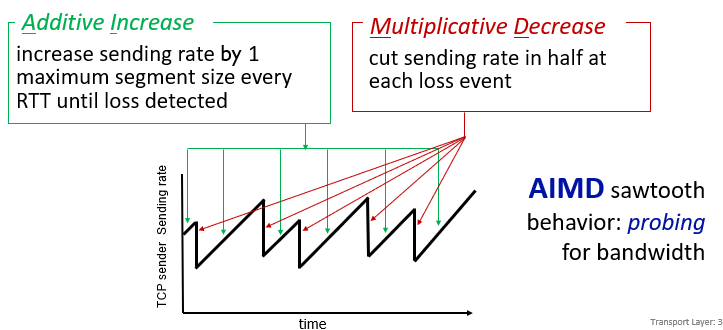
why AIMD
- 非同步的
details
- last byte sent - last byte ACKed <= congestion window
- 超過可能發生壅塞
- 不要超出自己的cwnd

TCP slow start p3.127
先發一個MSS,如果沒有congestion,double cwnd
- 初始傳輸效率低,指數增加
when should 變成線性增加?
- 超過ssthresh(slow start threshold)
- ssthresh閾值
- 設置為
的cwnd
- 設置為
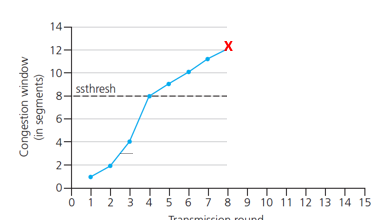
summary(自己再看一下) p3.129
Slow start
congestion avoidance(沒事 還是可以增加cwnd)
fast recovery
- 沒人會考數值
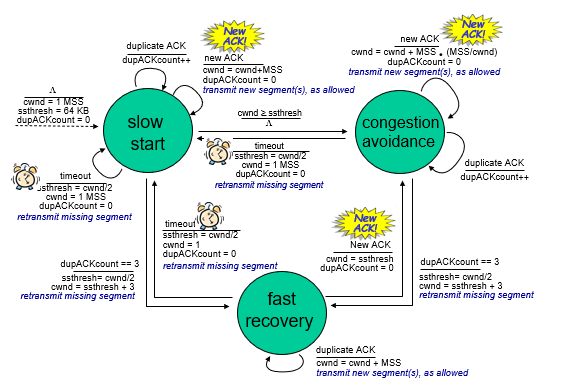
Slow start
- 根據duplicate ACK判斷網路中的發生狀況
- 收到new ACK, 增大cwnd
- 如果cwnd >= ssthresh
- 進入congestion avoidance
congestion avoidance
- 如果timeout
- 回到slow start, 降低ssthresh
- 如果dupACK == 3
- 進入fast recovery
- 重傳遺失的segment
fast recovery
- timeout 就回到最初的起點
- ssthresh = cwnd / 2
- cwnd = 1
- dupACK = 0
TCP CUBIC(沒甚麼特別的,看過就好)
congestion state
- 會壅塞的永遠都會壅塞
- 傳統TCP AIMD
- 可以減半,也可以減到剩1
- 現代TCP CUBIC
- 讓sending rate上升的更快
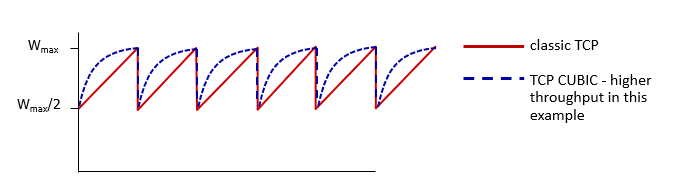
慢慢增加congestion window
- 去找網路中最大的through put
如果網路中存在bottle neck
- 就會一直存在
接近峰值(K)慢一點
不然就快一點
- K 類似於臨界點,即
TCP and the congested “bottleneck link” p3.132
只會有一段
- TCP CUBIC就是在找這一整段路最大的through put
塞住的router的buffer會一直保持幾乎是滿的狀態
如果存在bottleneck link
- 增加傳出速率,不會提高through put
- 反而RTT會變大,故藉此了解網路中是否發生壅塞
Goal: “keep the end-end pipe just full, but not fuller”
Delay-based TCP congestion control p3.134
比較RTT
- 時間
比較cwnd/RTT
- through put
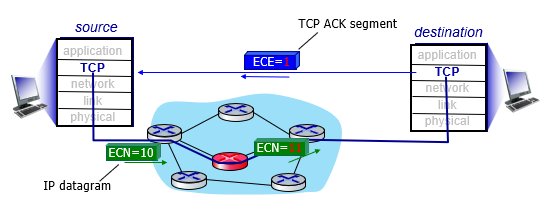
Explicit congestion notification (ECN)
network-assisted
- router會修改IP header的ECN
- 表示congestion
還有一個欄位紀錄congestion
- ECE
- transport layer標記的
Is TCP Fair?
原則上是公平的,在以下的假設情況下
- same RTT
- number of session is fixed
如果是 parallel TCP 就會比較快
Evolution of transport-layer functionality p3.141
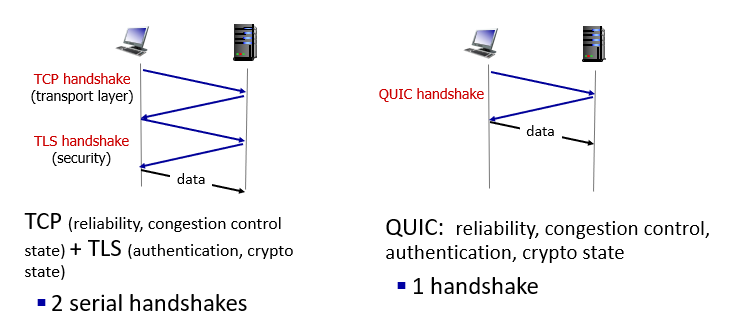
QUIC: quic UDP internet connections(看過就好) p3.143
傳統的TCP+TLS
- 會有兩個連續的handshake
- 存在HOL
- head of line blocking
QUIC
- 只有一個handshake
- parallelism
- no HOL blocking