S6--Chap6--Supplementary-Speech Precessing-2025
Chap6–Supplementary-Speech Precessing-2025
Outline
- Introduction
- Speech Production
- Speech Signal Representation
- Speech Coding
- Speech Synthesis
- Automatic Speech Recognition
Introduction
發聲 (Articulation):
圖的左邊部分展示了人類的發聲器官,像是聲帶和嘴巴。當我們說話時,這些器官會振動並產生聲波。圖中也顯示了這些聲波的波形。
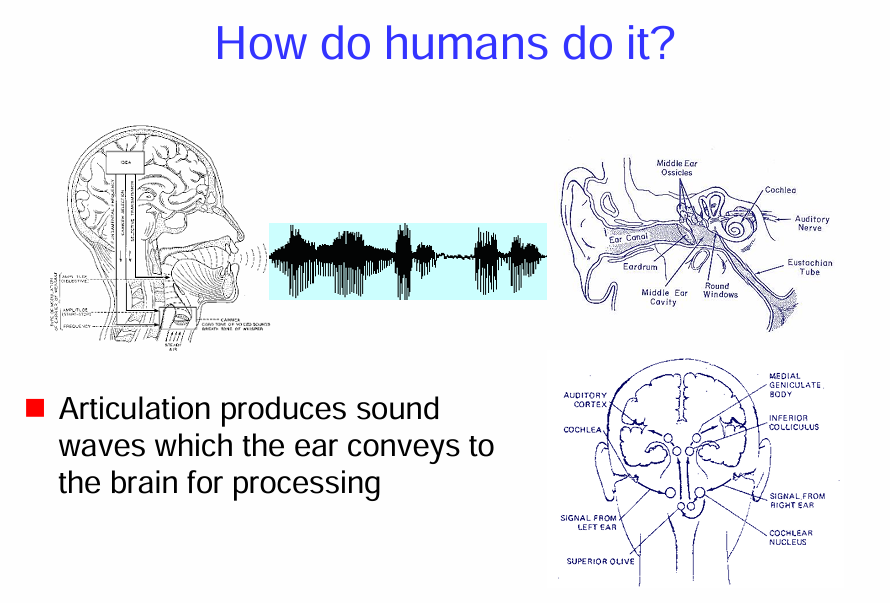
聲音傳入耳朵 (Sound Waves Conveyed to the Ear): 中間的圖是耳朵的結構。
- 聲波會先進入耳道 (Ear Canal)。
- 聲波撞擊耳膜 (Eardrum),使耳膜振動。
- 耳膜的振動會傳遞到中耳聽小骨 (Middle Ear Ossicles),這些小骨會放大振動。
- 放大的振動會傳遞到充滿液體的耳蝸 (Cochlea)。
大腦處理聲音 (Brain Processing): 圖的右下方顯示了聲音信號如何從耳朵傳到大腦。
- 耳蝸內的毛細胞會將這些振動轉換成神經信號。
- 這些信號會通過聽覺神經 (Auditory Nerve)傳送到腦幹的一些結構,像是耳蝸神經核 (Cochlear Nucleus)和上橄欖核 (Superior Olive)。
- 信號接著會傳遞到下丘 (Inferior Colliculus)和內側膝狀體 (Medial Geniculate Body)。
- 最後,這些信號會到達大腦的聽覺皮層 (Auditory Cortex),在這裡,大腦會處理這些信號,讓我們能夠理解聲音的內容,像是語言。
語音辨識 (Speech Recognition) 的過程
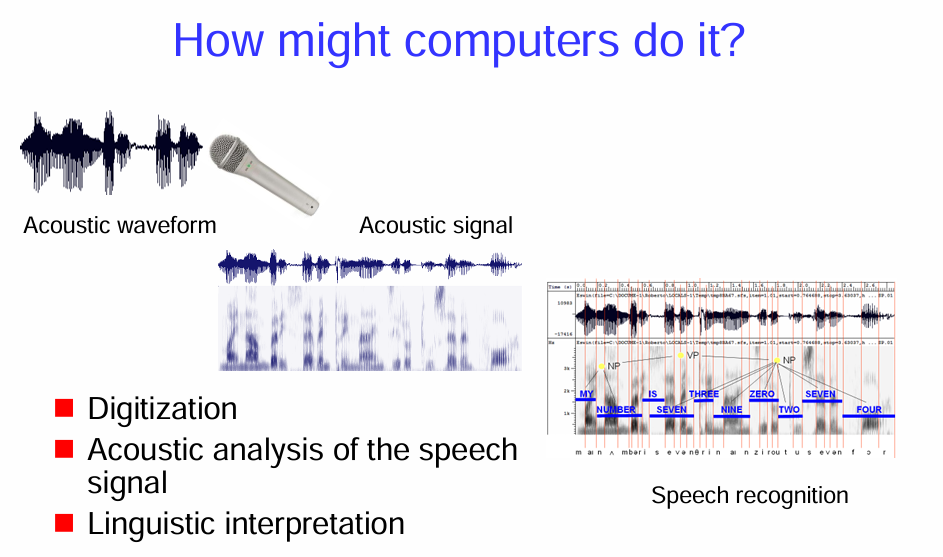
- 數位化 (Digitization):
圖片的左上方顯示了一個聲波波形 (Acoustic Waveform),這是人類說話時產生的聲音的物理表示。
旁邊的麥克風 (Microphone) 代表電腦如何接收這個聲波並將其轉換成聲學訊號 (Acoustic Signal)。
數位化 這個步驟指的是將這個連續的類比聲學訊號轉換成電腦可以處理的離散的數字訊號。這通常涉及到以一定的頻率對聲波的振幅進行採樣,並將這些採樣值量化成數字。
- 語音訊號的聲學分析 (Acoustic analysis of the speech signal):
圖片的中間部分展示了對聲學訊號進行分析的結果。下方類似頻譜圖的影像顯示了不同時間點聲音的頻率成分和強度。
這個步驟的目的是從數位化的聲學訊號中提取有意義的聲學特徵 (Acoustic Features)。這些特徵可以代表語音中的基本聲音單元,例如音素 (phonemes)。常用的聲學特徵包括梅爾頻率倒譜係數 (MFCCs) 等。
- 語言學理解 (Linguistic interpretation):
圖片的右下方顯示了語音辨識 (Speech Recognition) 的結果。上方是原始的聲波波形,下方則是電腦辨識出的文字:「MY NUMBER IS THREE ZERO SEVEN ZERO FOUR」。
這個步驟利用語言模型 (Language Model) 和聲學模型 (Acoustic Model) 來將提取出的聲學特徵序列轉換成文字序列。
聲學模型 負責將聲學特徵與可能的音素或音節對應起來。
語言模型 則考慮詞語之間的統計關係和語法規則,以提高辨識的準確性,例如,”my number is” 後面更可能出現數字而不是其他詞語。
圖中還顯示了一些更底層的分析,例如音素的切分和詞性的標註 (例如 NP 代表名詞短語,VP 代表動詞短語),這表明更複雜的語言學處理可能參與其中,以幫助理解語音的意義。
語音鏈
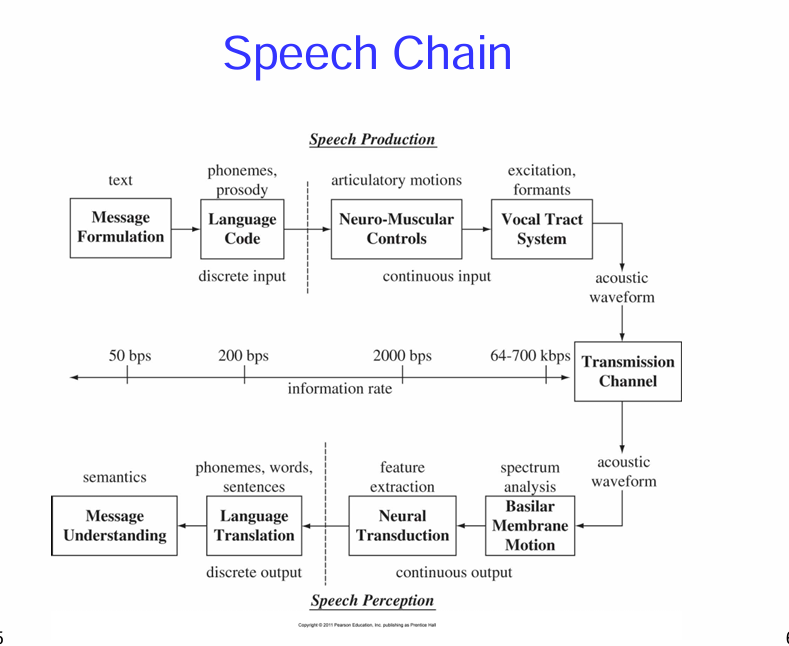
上半部:語音產生 (Speech Production)
Message Formulation (訊息形成):
這是說話的起點。說話者首先在大腦中構思想要傳達的訊息和想法,以文字 (text) 的形式存在。
Language Code (語言編碼):
接著,這個文字訊息會被轉換成語言的編碼,包括音素 (phonemes,語音中最小的發音單位) 和韻律 (prosody,語調、語氣等)。這是一個將抽象的想法轉化為具體的語言符號的過程,輸出是離散的 (discrete) 語言單位。
圖中標示的資訊速率約為 200 bps (bits per second)。
Neuro-Muscular Controls (神經肌肉控制):
大腦發出指令,控制發聲器官 (如聲帶、舌頭、嘴唇等) 的肌肉運動 (articulatory motions)。這個階段將離散的語言編碼轉化為連續的 (continuous) 肌肉運動指令。
圖中標示的資訊速率約為 2000 bps。
Vocal Tract System (聲道系統):
受到神經肌肉的控制,發聲器官產生聲波。聲帶的振動產生聲源 (excitation),而聲道的形狀和共鳴特性會塑造聲音的頻率成分,形成共振峰 (formants)。
最終產生的是聲學波形 (acoustic waveform),這是可以被聽到的聲音信號。
Transmission Channel (傳輸通道):
聲學波形通過空氣或其他介質傳播到聽者的耳朵。
圖中標示的資訊速率很高,約為 64-700 kbps。
下半部:語音感知 (Speech Perception)
Acoustic Waveform (聲學波形):
這是聽者耳朵接收到的聲音信號,與語音產生端發出的聲學波形相同。
Basilar Membrane Motion (基底膜運動):
聲音進入耳朵後,會引起內耳耳蝸中的基底膜產生振動 (motion)。基底膜的不同部位對不同頻率的聲音產生最大的響應,這是一個將聲學信號轉換為神經信號的過程,輸出是連續的。
Neural Transduction (神經轉換):
基底膜的振動會刺激聽覺神經纖維,將機械振動轉換為神經脈衝 (feature extraction,特徵提取)。大腦開始提取聲音中的重要特徵。
Language Translation (語言翻譯):
大腦對提取出的語音特徵進行分析,將其與儲存的語言知識 (包括音素、詞彙、語法、句子結構等) 進行匹配,從而識別出音素、詞語和句子 (phonemes, words, sentences)。這是一個將連續的神經信號轉化為離散的語言單位的過程,輸出是離散的。
Message Understanding (訊息理解):
最後,聽者理解接收到的語言訊息的含義 (semantics),完成了語音溝通的閉環。
整體概念:
語音鏈強調了語音溝通是一個涉及說話者和聽者的複雜過程。
它展示了訊息從說話者的大腦中的概念,經過語言編碼、生理發聲、物理傳播,再到聽者的耳朵接收、神經處理,最終被理解的完整流程。
圖中也標示了在不同階段的信息速率,可以看出信息在編碼和傳輸過程中經歷了不同的形式和速率。
Part 1- Speech Production
語音產生的基本機制
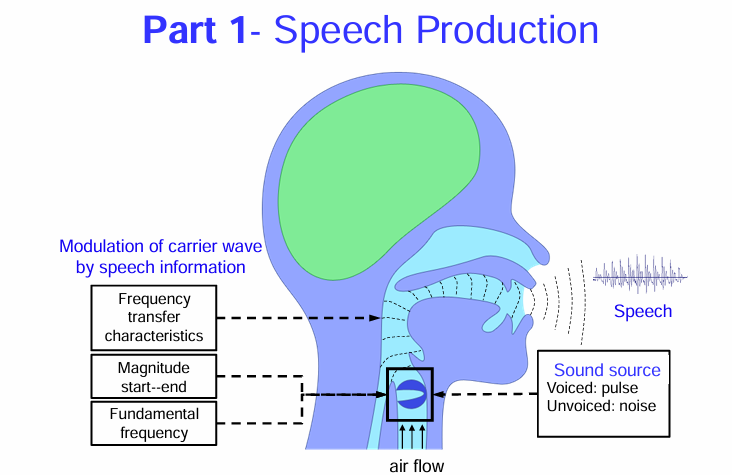
氣流 (air flow): 圖的下方顯示了向上的箭頭,表示空氣從肺部向上流動。這是產生語音的基礎。
聲源 (Sound source):
圖的中間部分著重在喉部。這裡有一個方框標示著聲帶 (雖然圖中沒有詳細繪製)。
方框旁邊的文字說明了聲源的兩種主要形式:有聲 (Voiced): 脈衝 (pulse):當空氣通過振動的聲帶時,會產生一系列快速的氣流脈衝,形成有聲語音,例如母音和一些子音(如 /b/, /d/, /g/, /v/, /z/ 等)。右邊的波形示意圖也顯示了這種規律的脈衝狀特性。 無聲 (Unvoiced): 噪音 (noise):當空氣通過張開的聲帶,並在口腔或咽喉的某個部位產生摩擦或阻塞時,會產生湍流,形成無聲語音,例如 /s/, /f/, /ʃ/, /θ/ 等。右邊的波形示意圖會呈現出更不規則的噪音狀特性。調制載波 (Modulation of carrier wave by speech information): 圖的左邊部分說明了聲帶產生的基本聲音(可以想像成一個「載波」)是如何被進一步塑造成不同的語音的。這個過程涉及到:
頻率傳遞特性 (Frequency transfer characteristics): 這指的是聲道(包括咽喉、口腔和鼻腔)的形狀和大小會對通過的聲音的不同頻率產生不同的共振和衰減作用。改變聲道的形狀(例如通過移動舌頭、嘴唇和下巴)可以塑造出不同的母音和子音。
幅度起始和結束 (Magnitude start-end): 這指的是語音的音量和持續時間。我們可以控制發聲的強弱以及每個音素的長短。
基頻 (Fundamental frequency): 這主要是由聲帶振動的頻率決定的,它決定了我們聲音的音高。我們可以通過控制聲帶的鬆緊來改變基頻,產生語調的變化。
語音 (Speech): 圖的右上方顯示了最終產生的語音波形,它是經過聲帶振動產生基本聲音,然後再經過聲道調制形成的複雜聲波。
更簡化的語音產生模型 (Model of speech production)
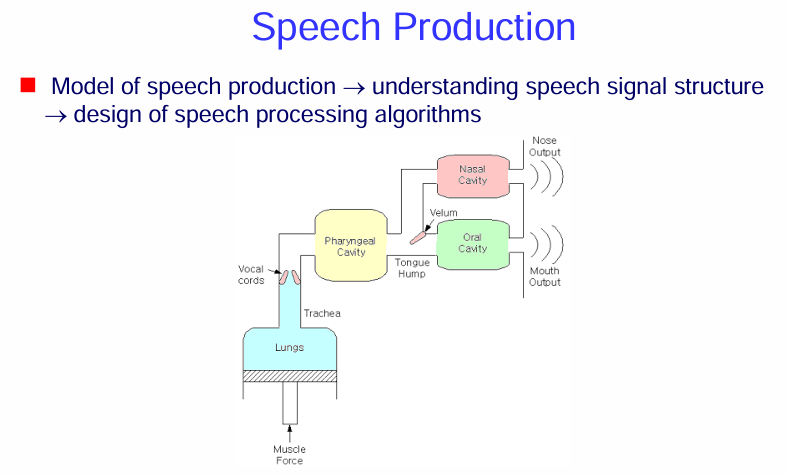
這張圖的核心概念是:
語音的產生始於肺部提供的氣流。
氣流通過聲帶振動(或不振動)產生基本的聲音。
這個基本的聲音通過聲道 (vocal tract),包括咽腔、口腔和鼻腔,這些腔體的形狀和連接方式受到發聲器官(如舌頭、嘴唇、軟顎)的控制。
聲道的共鳴特性會對原始聲音進行塑形和過濾,產生各種不同的語音。
模型的重要性:
圖片的上方文字說明了這個語音產生模型的重要性:
理解語音訊號結構 (understanding speech signal structure): 通過了解語音是如何產生的,我們可以更好地理解語音訊號的物理特性,例如頻率成分、共振峰 (formants) 等。這些特性與發聲器官的運動和聲道的形狀密切相關。
設計語音處理演算法 (design of speech processing algorithms): 對語音產生過程的理解可以指導我們設計更好的語音處理演算法,例如:
語音辨識 (Speech Recognition): 了解語音的聲學特性如何對應到發音單元(音素)可以幫助我們建立更準確的聲學模型。
語音合成 (Speech Synthesis): 模擬人類的發聲過程可以產生更自然、更像人類的合成語音。
語音編碼 (Speech Coding): 了解語音訊號的冗餘和重要成分可以幫助我們更有效地壓縮語音資料。
模型
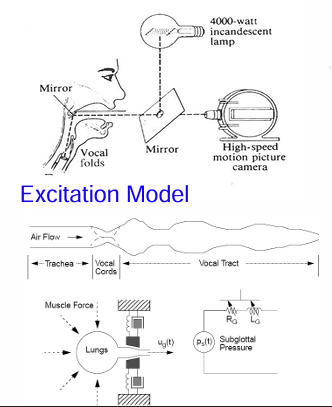
這個模型的目的是:
解釋聲帶如何基於來自肺部的氣流和自身的物理特性產生振動。 機械模型試圖用物理原理來描述這個過程。
使用電路類比來簡化和分析聲帶的振動特性。 電路分析的工具可以用於研究聲帶振動的頻率、幅度等特性。
為語音合成和語音分析提供數學基礎。
通過建立聲帶振動的數學模型,可以更好地模擬和理解語音的產生過程。
總而言之,這張圖片深入探討了語音產生的激勵源,也就是聲帶的振動。它結合了高速攝影的實驗觀察、簡化的氣流和聲道示意圖,以及嘗試用機械模型和電路類比來描述聲帶振動的物理機制。這對於理解語音訊號的fundamental特性至關重要。
語音產生的線性源-濾波器模型
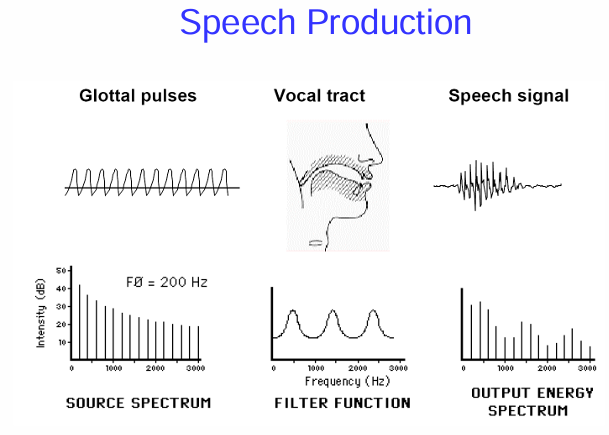
總結來說,這張圖用頻譜的概念清晰地展示了語音產生的線性源-濾波器模型 (Linear Source-Filter Model of Speech Production):
聲帶振動產生一個包含基頻和諧波的原始聲源 (Source)。
聲道作為一個具有特定共振特性的濾波器 (Filter)。
原始聲源通過聲道這個濾波器後,其頻譜被塑形,形成最終的語音訊號 (Output)。 語音訊號的頻譜特徵(例如共振峰的位置和幅度)反映了發聲時聲道的形狀,而聲道的形狀是由發音器官的運動控制的,這就產生了不同的語音。
這個模型是語音學和語音處理領域中一個非常重要的概念,它幫助我們理解語音的聲學特性是如何產生的,並為語音分析、合成和辨識等技術提供了理論基礎。
數位語音產生模型 (Complete Digital Model)
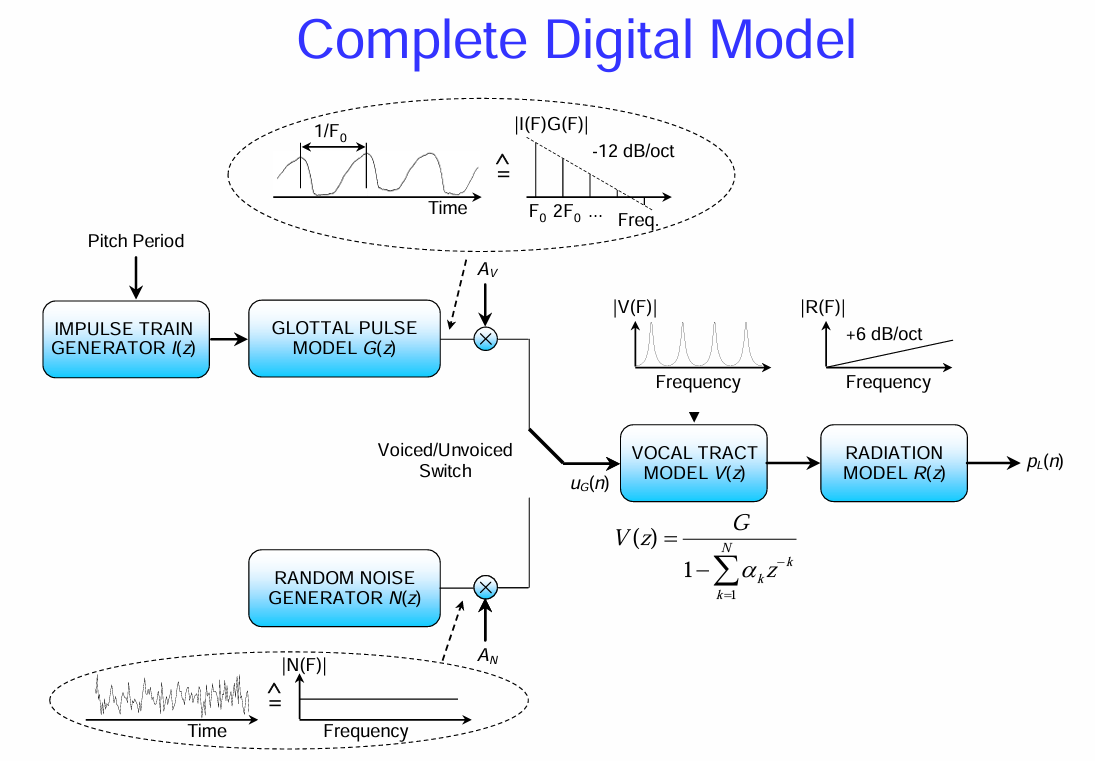
這張圖片展示了一個更完整的數位語音產生模型 (Complete Digital Model)。它將之前討論的聲源-濾波器模型轉化為一個數位訊號處理的流程圖,更貼近電腦如何模擬和處理語音。
讓我們逐步解析這個模型:
激勵源 (Excitation Source): 模型的最左邊有兩個主要的激勵源,對應於有聲語音和無聲語音:
脈衝串產生器 I(z) (Impulse Train Generator I(z)):
在有聲語音 (Voiced) 的情況下,聲帶的振動產生週期性的脈衝。這個產生器模擬的就是這樣一個脈衝序列,脈衝之間的間隔是基音週期 (Pitch Period, 1/F₀),其中 F₀ 是基頻。
上方的橢圓框示意了時域的脈衝串和其頻域的表示。在頻域,它表現為在基頻及其諧波處有能量峰值,整體幅度隨著頻率升高而衰減(大約 -12 dB/oct)。
隨機雜訊產生器 N(z) (Random Noise Generator N(z)):
在無聲語音 (Unvoiced) 的情況下,聲帶不振動,而是產生湍流噪音。這個產生器模擬的就是一個隨機雜訊訊號。
下方的橢圓框示意了時域的隨機雜訊和其頻域的表示。在頻域,它具有更平坦的頻譜,能量在較寬的頻率範圍內分佈。
聲源模型 G(z) (Glottal Pulse Model G(z)):
來自脈衝串或雜訊的激勵訊號會通過聲門脈衝模型。這個模型試圖更精確地模擬聲帶振動產生的氣流脈衝的形狀,而不僅僅是理想的脈衝串。它可能包含一些濾波特性,以使激勵訊號的頻譜更接近真實的聲門脈衝。
和 分別是有聲和無聲激勵的幅度控制。
Voiced/Unvoiced Switch (有聲/無聲切換): 這個開關決定了在某個時間點使用哪種激勵源,這取決於當前發出的音素是有聲還是無聲。
聲道模型 V(z) (Vocal Tract Model V(z)):
經過聲源模型處理後的激勵訊號會進入聲道模型。這個模型用一個數位濾波器來表示聲道的共振特性。
圖中給出了一個常見的聲道模型的數學表示:
這是一個全極點 (all-pole) 的線性時不變 (LTI) 濾波器,其中 G 是增益,是預測係數,它們決定了濾波器的共振頻率和帶寬,從而模擬聲道的共振峰。N 是模型的階數,通常取決於需要模擬的共振峰數量。 表示延遲單元。
上方的頻譜 ∣V(F)∣ 示意了聲道模型的頻率響應,顯示了幾個共振峰(能量峰值)。
輻射模型 R(z) (Radiation Model R(z)):
聲音從嘴唇和鼻孔輻射出去時,其頻譜也會發生變化。輻射模型 用來模擬這種效應。
一個簡化的輻射模型通常近似為一個高通濾波器,它會增強高頻成分,頻率響應大約是 +6 dB/oct。
上方的頻譜 ∣R(F)∣ 示意了輻射模型的頻率響應,顯示幅度隨著頻率升高而增加。
輸出語音 p(n) (Output Speech p(n)):
最終,經過激勵、聲道濾波和輻射效應處理後,就得到了合成的數位語音訊號 p(n)。
這個數位模型的意義在於:
它提供了一個在電腦上合成語音的框架。 通過控制激勵源的參數(如基頻、幅度)和聲道模型的係數(
),可以合成出不同的語音。
它有助於理解語音訊號的產生過程,並將其分解為不同的組成部分(激勵、聲道、輻射)。
這個模型是許多語音處理技術的基礎,例如參數語音合成 (parametric speech synthesis) 和語音分析。 通過分析真實語音訊號,可以估計出這個模型中的參數,從而提取語音的特徵。
總之,這個「完整的數位模型」將人類語音產生的物理過程抽象為一個數位訊號處理系統,為在電腦上進行語音的模擬和處理提供了理論和實踐基礎。
Part2 Speech Signal Representation
語音訊號表示的重要性

總而言之,這張圖片是第二部分的引言,它強調了語音訊號表示的重要性,並預告了接下來的內容將會討論如何從語音訊號中提取出其核心的產生要素:激勵源和聲道濾波器。 這是語音訊號分析的關鍵步驟,為後續的語音編碼、合成和辨識等應用奠定了基礎。
時域分析
這張圖片介紹了語音訊號的 時域分析 (Time Domain Analysis),並提出了一個重要的假設:
假設 (Assumption): 語音訊號的特性隨時間變化相對緩慢,因此可以使用 “短時 (Short-Time)” 處理。
短時處理 (Short-Time Processing): 由於語音特性在短時間內近似穩定,我們可以將語音訊號分成許多短小的時間片段(幀),然後對每一幀進行分析。
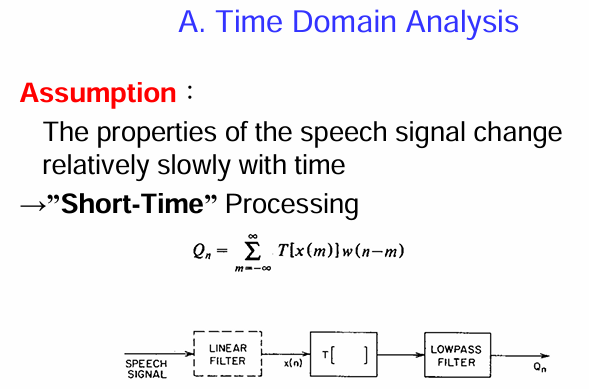
公式: 圖中給出了一個通用的短時處理公式:
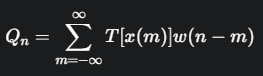
這個公式表示,對於語音訊號 x(m) 的某種變換 T[x(m)],我們使用一個窗函數 (window function) w(n−m) 來選取以時間點 n 為中心的短時片段,並對其進行求和,得到短時處理的結果
。窗函數 w(n−m) 在 n−m 接近 0 時有較大的值,遠離 0 時值趨近於 0,從而實現了對局部訊號的加權。
方框圖: 下方的方框圖展示了一個可能的短時分析流程:
語音訊號 (SPEECH SIGNAL): 輸入的待分析語音訊號。
(可選) 線性濾波器 (LINEAR FILTER): 在進行短時分析之前,可能對語音訊號進行預處理,例如預加重 (pre-emphasis)。
窗函數處理 T[ ] (T[ ]): 這一步示意了將語音訊號 x(n) 乘以窗函數 w(n−m) 的過程,即選取短時片段。T[x(n)] 可以是直接截取 x(n) 或對其進行某種變換。
低通濾波器 (LOWPASS FILTER): 對窗函數處理後的訊號進行低通濾波,以平滑短時分析的結果,得到緩慢變化的時域特徵
。
簡而言之,時域分析基於語音訊號在短時間內特性穩定的假設,通過對語音訊號的短時片段進行處理,提取隨時間變化的特徵。窗函數是實現短時分析的關鍵工具。
“短時 (Short-Time)” 處理
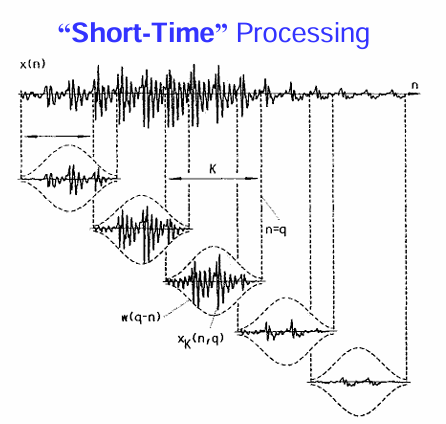
好的,這張圖片更直觀地解釋了 “短時 (Short-Time)” 處理 的概念。
圖中:
x(n): 代表原始的語音訊號,它是一個隨時間 n 變化的波形。
w(q-n): 代表窗函數,圖中是一個以 q 為中心(當前分析的時間點)的加權函數,通常具有中間高、兩端低的形狀(例如高斯窗)。
x_K(n, q): 代表加窗後的短時語音片段。它是原始語音訊號 x(n) 與窗函數 w(q−n) 在時間上相乘的結果。可以看到,只有在窗函數不為零的區域內的語音訊號被保留下來,並根據窗函數的形狀進行加權。
K: 表示窗的長度,決定了每次分析的時間範圍。
箭頭和虛線: 展示了隨著時間 q 的推移,窗函數在語音訊號上滑動,選取出不同的短時片段進行分析。
簡而言之,短時處理就是用一個移動的「窗戶」觀察語音訊號,每次只分析窗戶內的一小段訊號。這樣做的目的是因為語音的特性在一個短時間範圍內可以近似認為是穩定的,方便我們提取隨時間變化的語音特徵。
短時能量 (Short-Time Energy) 和 平均幅度 (Average Magnitude)。
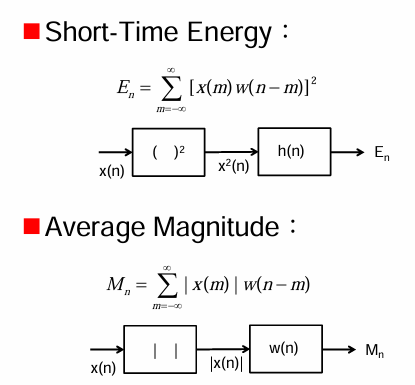
這張圖片介紹了兩個常用的短時時域特徵 (Short-Time Time Domain Features):
1. 短時能量 (Short-Time Energy):
公式:
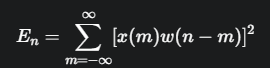
這個公式表示,對於語音訊號 x(m),首先用窗函數 w(n−m) 選取以時間點 n 為中心的短時片段,然後對該片段內所有取樣點的平方值進行求和,得到在時間 n 的短時能量
。能量反映了訊號的強度。
方框圖:
x(n): 輸入的語音訊號。
( )²: 對語音訊號的每個取樣點進行平方運算,得到
。
h(n): 代表窗函數 w(n)。這裡用 h(n) 可能只是為了表示一個線性系統(窗函數可以看作是一個有限長度的脈衝響應)。實際上,應該是乘以窗函數 w(n−m) 並求和。
E_n: 輸出的短時能量。
簡而言之,短時能量通過計算短時片段內訊號平方和來衡量該片段的能量大小。它可以用於區分語音中的清音段和濁音段,因為濁音段通常具有更高的能量。
2. 平均幅度 (Average Magnitude):
公式:
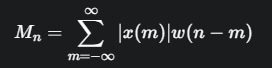
這個公式表示,對於語音訊號 x(m),首先用窗函數 w(n−m) 選取以時間點 n 為中心的短時片段,然後對該片段內所有取樣點的絕對值進行求和,得到在時間 n 的平均幅度
。平均幅度也是衡量訊號強度的一種方式。
方框圖:
x(n): 輸入的語音訊號。
| |: 對語音訊號的每個取樣點取絕對值,得到 ∣x(n)∣。
w(n): 代表窗函數 w(n)。同樣,實際操作是乘以窗函數 w(n−m) 並求和。
M_n: 輸出的平均幅度。
簡而言之,平均幅度通過計算短時片段內訊號絕對值之和來衡量該片段的平均強度。它與短時能量類似,但計算量較小,在某些應用中也很有用
平均過零率 (Average Zero-Crossing Rate)
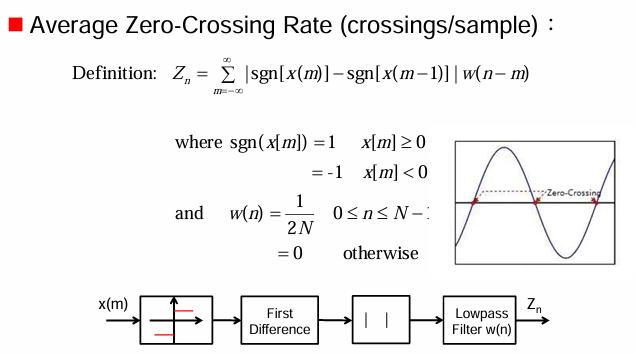
定義 (Definition):
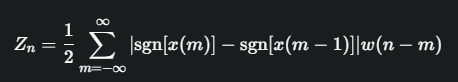
其中,符號函數 sgn[x(m)] 定義為:
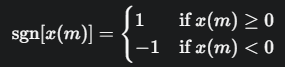
窗函數 w(n): 在這個例子中,窗函數是一個矩形窗 (rectangular window),定義為:
這裡的是為了對結果進行歸一化。
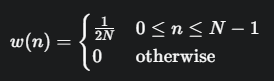
過零 (Zero-Crossing): 右上角的示意圖解釋了過零的概念。當訊號的幅度從正值變為負值,或從負值變為正值時,就發生了一次過零。
公式的意義: 公式中的 ∣sgn[x(m)]−sgn[x(m−1)]∣ 項,當相鄰兩個取樣點的符號不同時(即發生過零),其值為 ∣1−(−1)∣=2 或 ∣−1−1∣=2;當符號相同時,其值為 ∣1−1∣=0 或 ∣−1−(−1)∣=0。因此,這個公式實際上是在短時窗內計算訊號符號變化的次數(過零次數),並用窗函數進行加權平均。前面的1/2是為了將每次符號變化計為一次過零。
方框圖: 下方的方框圖展示了計算平均過零率的流程:
x(m): 輸入的語音訊號。
sgn[ ]: 計算每個取樣點的符號。
First Difference: 計算相鄰取樣點符號的差分 sgn[x(m)]−sgn[x(m−1)]。
| |: 取差分的絕對值,得到符號變化的指示(0 或 2)。
Lowpass Filter w(n): 實際上是乘以窗函數 w(n−m) 並求和(卷積),實現短時平均,得到平均過零率 Z_n。這裡用低通濾波器表示可能暗示了對過零次數進行平滑處理。
簡而言之,平均過零率衡量了語音訊號在短時間內穿越零值軸的頻率。它通常用於區分語音中的清音段和濁音段,因為清音(如摩擦音)通常具有比濁音更高的過零率。
短時分析中常用的幾種窗函數 (Windows)
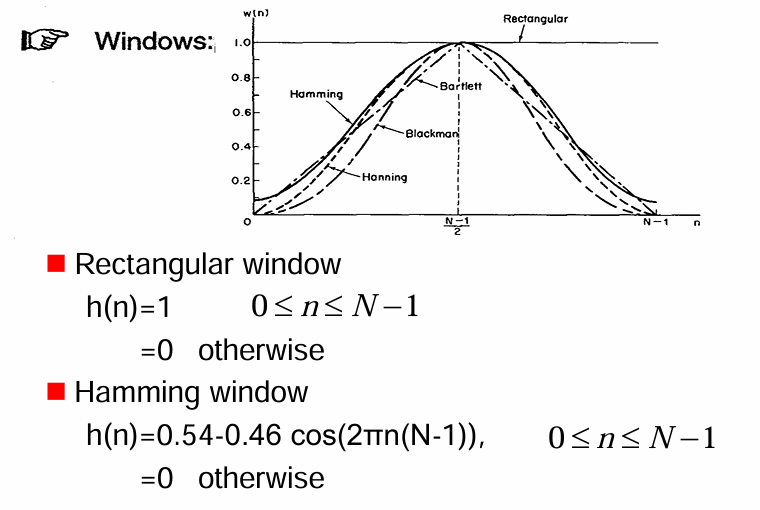
窗函數的作用是選取語音訊號的短時片段,並對片段內的取樣點進行加權,以減少直接截斷訊號可能引入的頻譜洩漏 (spectral leakage) 等問題。
圖中顯示了幾種常見的窗函數的形狀:
Rectangular (矩形窗): 圖中用實線表示,其形狀在窗的持續時間內是恆定的(幅度為 1),而在窗外則為 0。
Hamming (漢明窗): 用點劃線表示,其形狀類似於升起的餘弦函數,中間高,兩端逐漸降為接近 0 的值。
Bartlett (巴特利特窗): 用短劃線表示,其形狀為三角形,從中心向兩端線性地降為 0。
Blackman (布萊克曼窗): 用更細的點劃線表示,其形狀比漢明窗更平滑,主瓣更窄,旁瓣更小。
Hanning (漢寧窗): 用虛線表示,其形狀也類似於升起的餘弦函數,兩端恰好降為 0。
簡而言之,窗函數在短時分析中用於平滑地選取語音片段,減少頻譜分析時可能出現的人為干擾。不同的窗函數具有不同的時域和頻域特性,適用於不同的分析目的。矩形窗簡單但頻譜特性不佳,而漢明窗等其他窗函數則通過更平滑的加權來改善頻譜特性。
窗的長度 (Window Duration) 對短時分析的影響

窗長 N 的影響:
N 太小 (約等於 1 個基音週期):
→E_n (短時能量) 會劇烈波動 (will fluctuate)。
原因:如果窗長太短,只能捕捉到基音週期內的部分波形,能量會隨著窗的位置在基音週期內的不同相位而快速變化,無法反映語音段的整體能量特性。
N 太大 (約為幾個基音週期):
→E_n (短時能量) 的變化會非常緩慢 (will change very slowly)。
原因:如果窗長太長,會平均掉語音訊號在較長時間範圍內的能量變化,使得能量包絡的細節被平滑掉,無法捕捉到語音中快速發生的變化(例如音節之間的能量差異)。
實際應用中窗長的選擇建議:
對於 10kHz 的取樣率:
N 的合適範圍通常在 100-200 個取樣點。
這對應的時間長度為 10-20 毫秒 (ms)。
端點偵測 (End-Point Detection) 的演算法

演算法步驟:
初始靜音段假設: 假設錄音開始的前 100 毫秒只包含靜音。基於這段靜音,計算三個初始閾值:
- ITU (Initial Threshold for Upper level): 較高的能量閾值。
- ITL (Initial Threshold for Lower level): 較低的能量閾值。
- IZCT (Initial Zero-Crossing Threshold): 過零率閾值。
前向搜索高能量段: 從錄音開始向後搜索,找到平均幅度首次超過較高能量閾值 ITU 的時間點。這暗示語音可能開始出現。
後向搜索潛在端點: 從步驟 2 中找到的時間點開始向前(對於開始端點)或向後(對於結束端點)搜索,找到平均幅度首次低於較低能量閾值 ITL 的時間點。這個時間點被暫定選為語音的開始點 (N1) 或結束點 (N2)。
過零率校正(開始端點): 從暫定的開始點 N1 向前搜索,將短時過零率與閾值 IZCT 進行比較。如果在向後移動的過程中,過零率超過閾值 IZCT 達到 3 次或更多,則將開始點 N1 移回到第一次超過過零率閾值的時間點。否則,N1 就被最終確定為語音的開始點。這個步驟的目的是利用清音(通常具有較高過零率)的特性來更精確地定位語音的起始。
結束端點的類似處理: 對於語音的結束端點,採用與步驟 2-4 類似的過程,只是搜索方向相反。首先向前搜索超過 ITU 的點,然後向後搜索低於 ITL 的暫定結束點,最後利用過零率從暫定結束點向後進行校正。
簡而言之,這個端點偵測演算法首先利用能量閾值粗略地定位語音的可能開始和結束位置,然後利用過零率的特性對開始和結束點進行更精細的調整,特別是針對可能包含清音的語音段。 這種結合能量和過零率的方法在語音處理中是一種常見且有效的方法。
基於能量和過零率的端點偵測演算法的操作過程
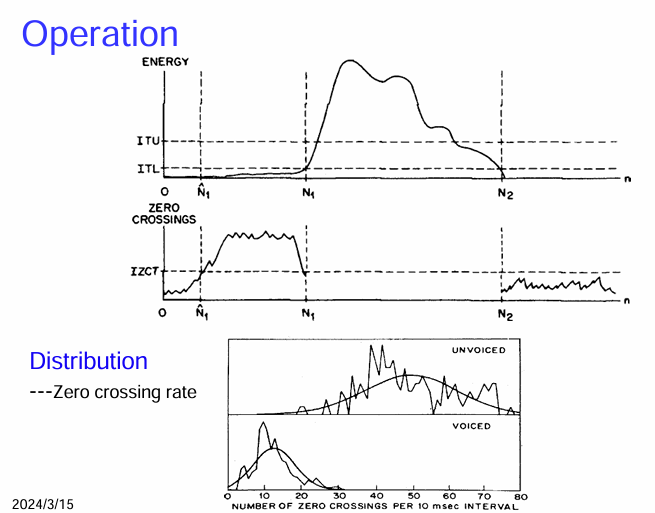
上半部分:操作 (Operation)

下半部分:分佈 (Distribution)
過零率分佈 (Zero crossing rate): 這個部分顯示了清音 (UNVOICED) 和濁音 (VOICED) 的過零率統計分佈。
- 清音: 通常具有較高的過零率,其分佈的峰值位於較高的過零次數。
- 濁音: 通常具有較低的過零率,其分佈的峰值位於較低的過零次數。
總而言之,這張圖通過能量和過零率隨時間的變化,以及清音和濁音的過零率分佈,形象地展示了端點偵測演算法的工作原理。能量用於粗略定位語音段,而過零率則用於更精細地判斷語音的起始和結束,尤其是在清音和靜音之間進行區分時。清音和濁音在過零率上的統計差異是這個算法中利用過零率進行判斷的基礎。
兩種常用的基音檢測 (Pitch Detection) 方法

- 短時自相關函數 (Short-Time Autocorrelation Function):
- 基於中心削波 (Center Clipping) 的基音檢測:


簡而言之,短時自相關函數是一種通過分析語音訊號與其延遲版本的相關性來估計基音週期的方法。對於濁音,自相關函數會在基音週期及其倍數的延遲處產生峰值。中心削波是一種預處理技術,通過抑制幅度較小的部分,可以增強自相關函數的週期性峰值,提高基音檢測的準確性。
3 級中心削波 (3-Level Center Clipping) 方法
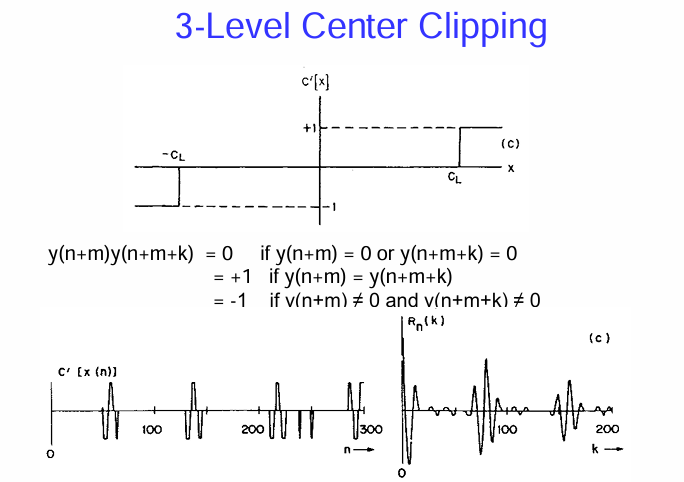
- 3 級中心削波函數 C’[x]:
- 簡化的自相關計算:
- 圖示 (c):



簡而言之,3 級中心削波是一種更激進的非線性處理方法,它將語音訊號的幅度量化為三個層級。結合簡化的自相關計算,這種方法可以在計算複雜度較低的情況下,仍然提供足夠的基音週期信息。它的優點在於對原始訊號的幅度變化不太敏感,可以更好地突出週期性成分。
中值平滑 (Median Smoothing) 的方法
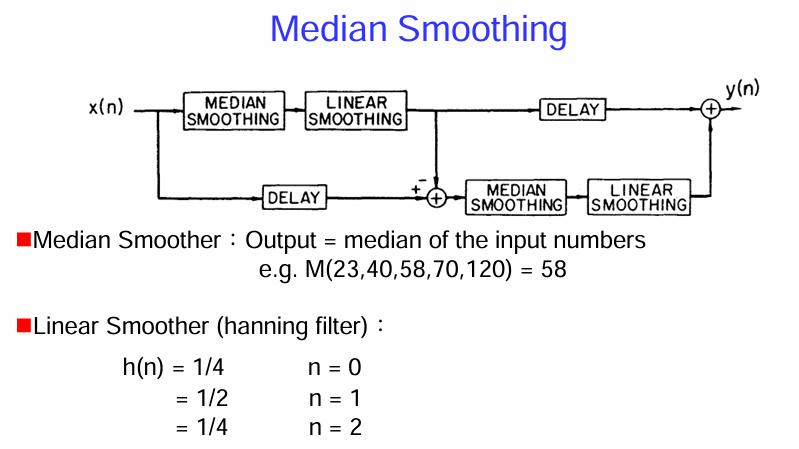
這張圖片介紹了一種中值平滑 (Median Smoothing) 的方法,並將其與線性平滑 (Linear Smoothing) 相結合。這個結構看起來像是用於後處理,以改善某些訊號(可能是基音檢測的結果)的平滑性和準確性。
- 中值平滑 (Median Smoothing):
- 線性平滑 (Linear Smoother - Hanning filter 的一個簡化版本):
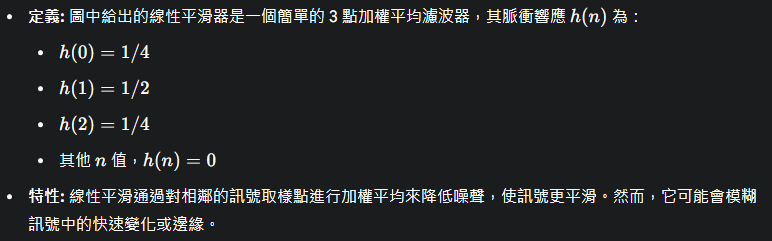
- 特性: 線性平滑通過對相鄰的訊號取樣點進行加權平均來降低噪聲,使訊號更平滑。然而,它可能會模糊訊號中的快速變化或邊緣。

這個複雜的結構可能旨在結合中值平滑去除噪聲和保留邊緣的優點,以及線性平滑進一步降低隨機波動的能力。通過相減和再次平滑下路徑的處理,系統可能試圖自適應地調整平滑的程度或提取某些特定的訊號成分。
簡而言之,這張圖片展示了一種利用中值平滑和線性平滑相結合的非線性平滑技術,其目的是在去除噪聲的同時,更好地保留訊號的特性。複雜的結構暗示了可能需要更精細地控制平滑的過程或提取訊號的特定信息。
語音訊號的 頻域分析 (Frequency Domain Analysis)
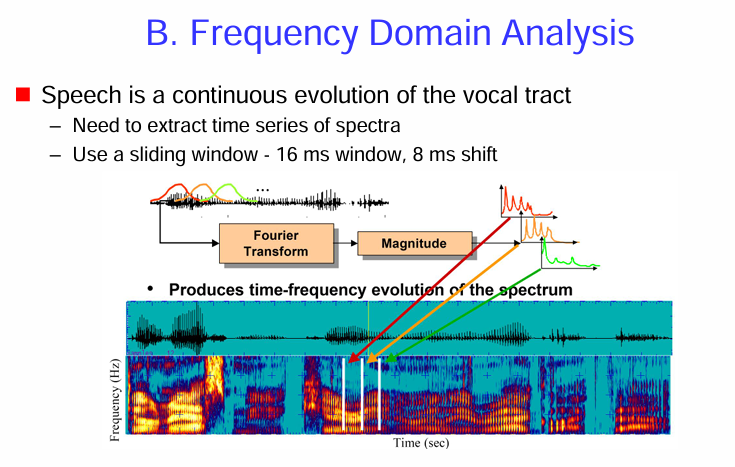
核心思想: 語音可以看作是聲道隨時間連續變化的結果,因此需要提取語音頻譜隨時間演變的資訊。
方法: 使用滑動窗 (sliding window) 對語音訊號進行短時傅立葉轉換 (Short-Time Fourier Transform, STFT)。

語譜圖的意義:

使用 傅立葉轉換 (Fourier Transform, FT) 的動機和定義

使用傅立葉轉換的動機 (Motivation):

定義 (Definition):

簡而言之,傅立葉轉換是一種強大的數學工具,它將信號從時域(時間的函數)轉換到頻域(頻率的函數),使得信號的頻率成分得以顯現。這對於分析語音的頻率結構至關重要,是頻域分析的基礎。
離散傅立葉轉換 (Discrete Fourier Transform, DFT)

由於電腦只能處理離散的數位信號,因此在語音處理中,我們通常使用 DFT 而不是連續傅立葉轉換。
離散傅立葉轉換的定義:

反離散傅立葉轉換 (Inverse Discrete Fourier Transform, IDFT):

短時傅立葉轉換 (Short-Time Fourier Transform, STFT)

STFT 是分析語音頻譜隨時間變化最常用的方法。
STFT 的概念:
- 由於語音訊號的特性是隨時間變化的(非穩態),直接對整個語音訊號進行傅立葉轉換會得到整個信號的平均頻譜,而丟失了頻譜隨時間變化的信息。STFT 通過對語音訊號進行分幀 (framing) 和對每一幀進行傅立葉轉換來解決這個問題。
STFT 的計算公式:


簡而言之,短時傅立葉轉換 (STFT) 是一種通過將語音訊號分成短小的幀,並對每一幀進行傅立葉轉換來分析語音頻譜隨時間變化的方法。窗函數用於平滑每一幀的邊界,而 hop size 決定了時間上的分析密度。STFT 的結果可以用來生成語譜圖,直觀地展示語音的時頻特性。
25000 點的語音頻譜 (25000-Point Speech Spectrum)
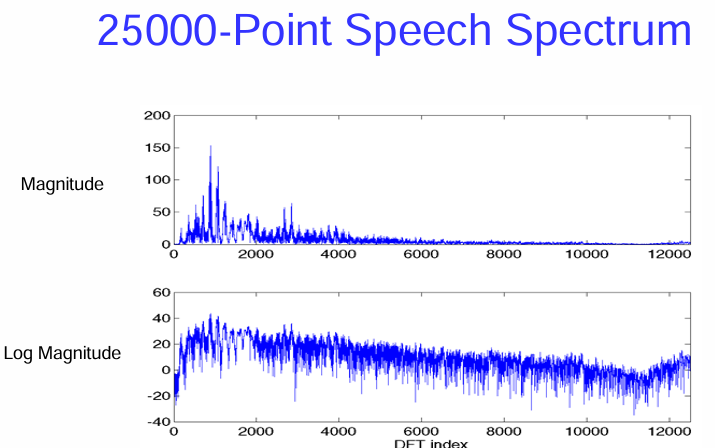
這表示對一段語音訊號進行了 25000 點的離散傅立葉轉換 (DFT),得到了頻域表示。
圖片包含兩個子圖,展示了頻譜的不同尺度:

簡而言之,這張圖片展示了語音訊號通過 25000 點 DFT 轉換到頻域後的幅度譜和對數幅度譜。頻譜顯示了語音信號在不同頻率上的能量分佈,是分析語音頻率特性的重要工具。幅度譜直接反映能量大小,而對數幅度譜則更利於觀察頻譜的整體形狀和低能量成分。
語譜圖 (Spectrogram) 的概念及其重要特性

語譜圖的定義和特性:


簡而言之,語譜圖是一種將語音訊號的頻率成分隨時間變化視覺化的強大工具。它通過短時傅立葉轉換得到,並以時間為橫軸、頻率為縱軸,顏色或灰度表示能量強度。語譜圖能夠清晰地展示語音的頻率結構和時間動態,對於語音分析和理解至關重要,並且存在時間和頻率解析度之間的權衡。
語譜圖 (Spectrogram) 的計算方法
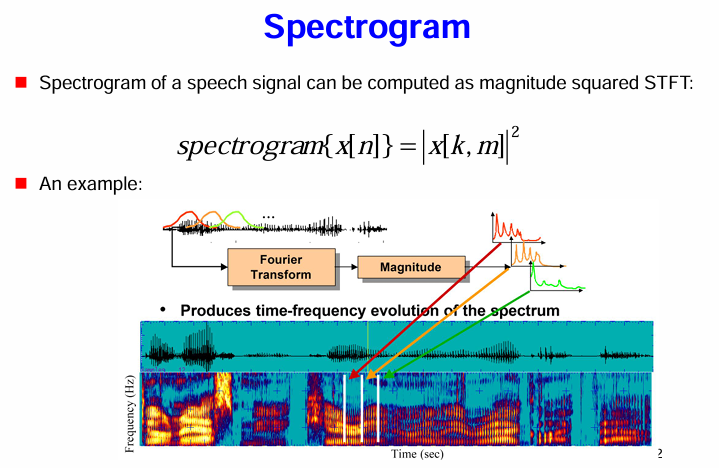
語譜圖的計算:

範例:

語譜圖的視覺化:
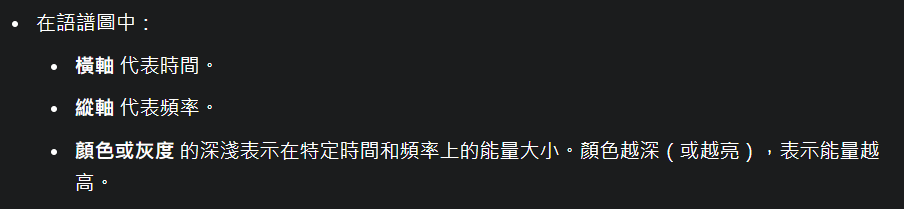
簡而言之,語譜圖是 STFT 幅度的平方,它直觀地展示了語音訊號的能量在時間和頻率上的分佈。它是分析語音頻率特性隨時間變化的關鍵工具,廣泛應用於語音分析、語音識別、語音合成等領域。
線性預測編碼 (Linear Predictive Coding, LPC)
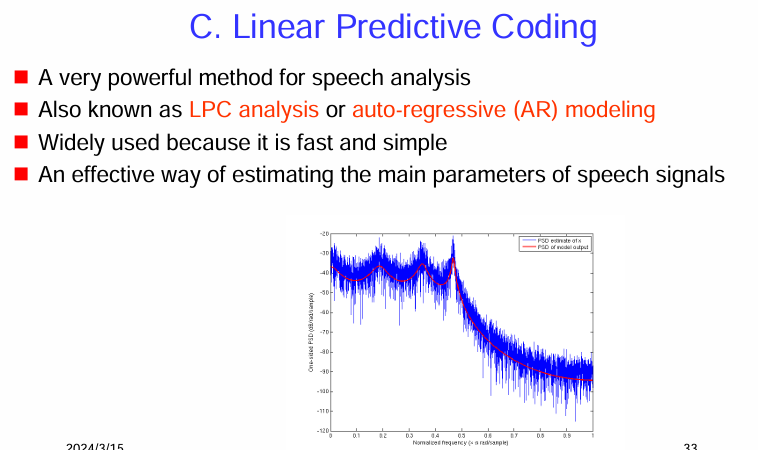
線性預測編碼 (LPC):

圖示:

簡而言之,線性預測編碼 (LPC) 是一種通過建立語音產生模型的自迴歸模型來分析語音信號的方法。它通過預測當前的語音取樣點來估計聲道和激勵源的參數,能夠用少量的參數有效地表示語音的頻譜包絡,並且由於其高效性而被廣泛應用。
線性預測編碼 (LPC) 的數學模型

全極點濾波器近似 (All-pole filter approximation):
- LPC 的核心思想是使用一個全極點 (all-pole) 濾波器來近似語音信號的聲道模型。如果極點的數量足夠多,這個全極點濾波器可以很好地模擬聲道的共振特性(共振峰)。
數位模型中的濾波器 H(z):
在數位模型中,聲道濾波器 H(z) 可以表示為輸出 X(z)(語音信號的 Z 轉換)與輸入 E(z)(激勵信號的 Z 轉換)的比值:

反向濾波器 A(z):
- 反向濾波器 A(z) 的定義如公式所示。如果將語音信號 X(z) 通過反向濾波器 A(z),理想情況下會得到激勵信號 E(z)。
時域表示:

簡而言之,LPC 通過假設當前的語音取樣點可以由過去的取樣點線性預測得到,並通過最小化預測誤差來估計預測係數 a_k。這些預測係數描述了一個全極點的聲道模型。激勵信號 e[n] 則是預測殘餘,包含了聲源的信息(例如脈衝串或噪音)。
線性預測編碼 (Linear Predictive Coding, LPC) 的核心思想和預測誤差

LPC 的命名由來:

預測誤差 (Prediction Error):

Yule-Walker 方程 (Yule-Walker Equation):
- 圖片中提到,當最小化預測誤差的均方值時,得到的預測係數 a_k 滿足 Yule-Walker 方程 (Yule-Walker Equation)。Yule-Walker 方程建立了語音信號的自相關函數與 LPC 係數之間的關係,是求解 LPC 係數的常用方法。
簡而言之,LPC 的基本思想是利用語音信號的相關性,將當前取樣點預測為過去取樣點的線性組合。預測的準確程度通過預測誤差來衡量,而 LPC 的目標就是找到使得預測誤差最小的預測係數。Yule-Walker 方程提供了一種計算這些預測係數的有效方法。
求解 LPC 係數的關鍵概念

短時分析 (Short-Time Analysis):
- 為了估計一組語音取樣點的預測係數,LPC 通常採用短時分析技術。這意味著將語音信號分成短幀,並在每一幀內進行 LPC 分析,因為語音的特性在短時間內近似穩定。
語音片段的定義:

短時預測誤差的定義:

正交性原理 (The Orthogonality Principle - 雖然圖片中沒有明確寫出這個術語):

簡而言之,為了在實踐中估計 LPC 係數,我們通常對語音信號進行短時分幀分析,並在每一幀內最小化預測誤差的平方和。正交性原理提供了一個數學工具,幫助我們找到使得這個誤差最小的預測係數。

求解 LPC 方程 (Solution of the LPC Equations) 的一種常用方法:自相關法 (Autocorrelation Method)

自相關法的基本假設:

預測誤差的範圍:

總預測誤差:

簡而言之,自相關法求解 LPC 係數的關鍵在於對語音片段進行加窗處理,使其在有限時間內非零,然後在這個有限長度的片段上最小化總的預測誤差平方和。這個最小化過程會導出基於語音片段自相關函數的線性方程組(Yule-Walker 方程),通過解這個方程組就可以得到 LPC 係數。
求解一個矩陣方程 (matrix equation) 來獲得 LPC 係數 (

矩陣方程的來源:

方程中的元素:

求解矩陣方程:

簡而言之,在 LPC 的自相關法中,求解 LPC 係數的過程歸結為解一個由語音片段自相關函數構成的 Toeplitz 矩陣方程。解這個方程組得到的
自相關矩陣的特性以及用於高效求解 Durbin 遞歸算法 (Durbin’s recursion)

自相關矩陣的特性:

Durbin 遞歸算法:



簡而言之,Durbin 遞歸算法利用自相關矩陣的 Toeplitz 特性,通過迭代的方式高效地計算出 LPC 係數和每一階的預測誤差能量。反射係數
自相關 (Autocorrelation) 和 線性預測編碼 (LPC) 在實際語音信號中的應用範例
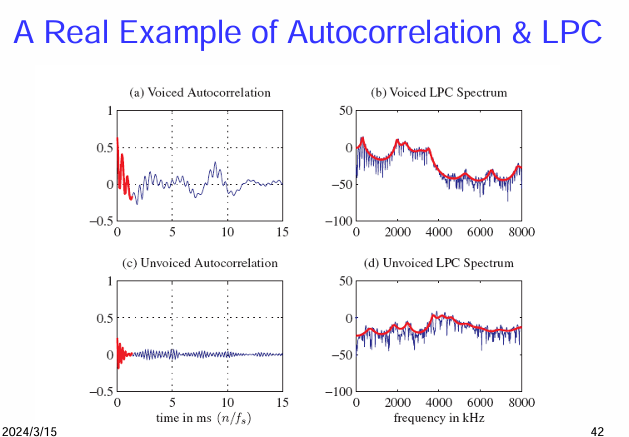
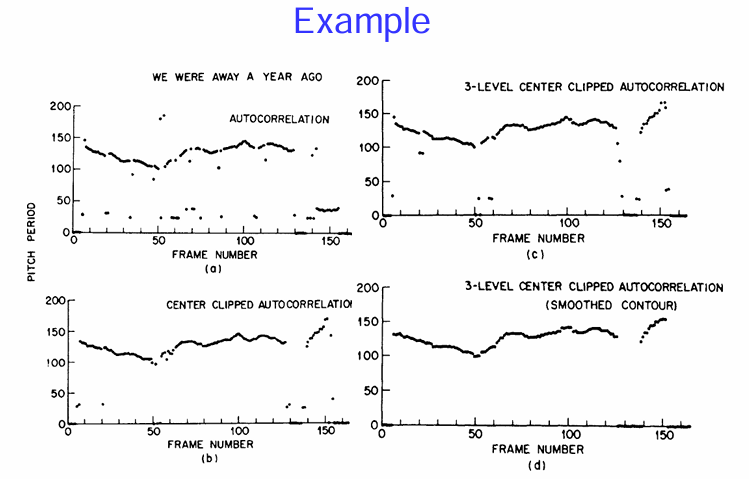
圖 (a) 濁音的自相關 (Voiced Autocorrelation):

圖 (b) 濁音的 LPC 頻譜 (Voiced LPC Spectrum):
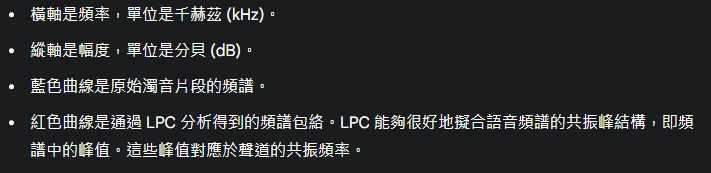
圖 (c) 清音的自相關 (Unvoiced Autocorrelation):

圖 (d) 清音的 LPC 頻譜 (Unvoiced LPC Spectrum):

總結來說,這個例子展示了:
- 自相關函數 可以有效地揭示濁音的週期性(基音週期),而清音則不具有這種週期性。
- LPC 分析 能夠用一組參數有效地表示語音的頻譜包絡,濁音的共振峰結構還是清音的總體頻譜形狀。這就是 LPC 在語音編碼中能夠實現高壓縮率的原因,因為只需要傳輸 LPC 係數和激勵信號的相關信息,而不需要傳輸原始的語音波形。
同態分析 (Homomorphic Analysis)

同態變換的定義:

同態分析的意義:

簡而言之,同態分析是一種旨在將語音產生模型中的卷積關係轉換為加法關係的技術,以便更容易地分離和分析激勵訊號和聲道特性。
同態分析 (Homomorphic Analysis of Speech Signal) 的模型和兩種常見的實現 (Implementation) 方法

語音產生的卷積模型 (Convolution Model):

同態分析的實現 (Implementation):

簡而言之,同態分析通過將語音產生的卷積模型轉換為加性模型,使得激勵和聲道特性可以更容易地分離。實現方法通常涉及在頻域進行對數運算,然後轉換回時域得到倒譜。基於複對數的方法保留了相位信息,而基於幅度對數的方法則丟失了相位信息。
倒譜 (Cepstrum)
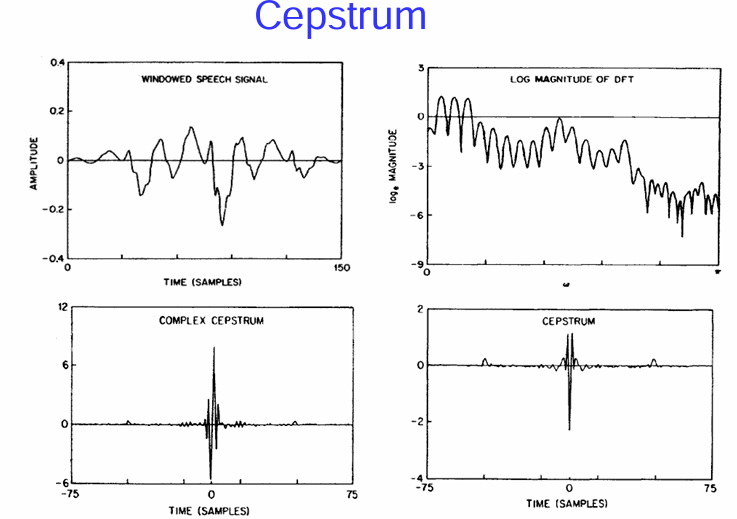
圖示說明:

倒譜的特性和應用:

總而言之,倒譜是同態分析在語音處理中的重要結果。它通過對語音訊號的頻譜進行對數運算和反傅立葉轉換,將卷積關係轉換為加法關係,從而在倒譜域分離聲道和激勵信息,方便進行基音檢測和聲道分析。
Part 3- Speech Coders
語音編碼 (Speech Coding) 的主要目的和兩種基本的壓縮類型

這張圖片介紹了 語音編碼 (Speech Coding) 的主要目的和兩種基本的壓縮類型。
語音編碼的主要目的:
降低位元率 (Reduction in bit rate is the primary purpose of speech coding): 語音編碼的核心目標是減少表示語音訊號所需的位元數,以便更有效地儲存和傳輸語音。
移除冗餘 (Previous bit stream can be compressed to a lower rate by removing redundancy in the signal): 降低位元率的關鍵在於去除語音訊號中的冗餘信息。語音訊號中存在多種冗餘,例如相鄰取樣點之間的高度相關性、人類聽覺系統對某些頻率不敏感等。
兩種壓縮類型:
無損壓縮 (Lossless compression):
- 原始訊號可以被精確地恢復 (original signal can be recovered exactly): 無損壓縮技術在壓縮和解壓縮過程中不會丟失任何信息。原始的數位語音訊號在解碼後與編碼前的訊號完全一致。
- 壓縮率通常較低 (compression ratios are typically lower),因為只能去除統計上的冗餘。常見的無損壓縮算法如 Huffman 編碼、算術編碼等。
有損壓縮 (Lossy compression):
- 原始訊號不能被精確地恢復 (original signal can not be recovered exactly): 有損壓縮技術在壓縮過程中會丟失一些信息,這些丟失的信息通常是人類聽覺系統不太敏感的部分。
- 壓縮率通常較高 (compression ratios are typically higher),因為可以去除感知上的冗餘。大多數語音編碼算法都是有損的,例如 PCM、DPCM、ADPCM、LPC 聲碼器等。目標是在可接受的失真程度下實現最大的壓縮。
簡而言之,語音編碼的主要目標是降低表示語音所需的位元數,通過移除訊號中的冗餘來實現。根據是否允許信息丟失,語音編碼可以分為無損壓縮和有損壓縮兩種主要類型。語音編碼在語音通訊、語音儲存等領域至關重要。
科學家

介紹了兩位在資訊理論和通訊理論領域有著卓越貢獻的科學家:
克勞德·艾爾伍德·香農 (Claude Elwood Shannon) (1916年4月30日 – 2001年2月24日) 是一位美國數學家、電子工程師和密碼學家,被譽為 「資訊理論之父 (the father of information theory)」。他的工作奠定了現代資訊時代的理論基礎。
哈里·奈奎斯特 (Harry Nyquist) (1889年2月7日 – 1976年4月4日) 是一位對通訊理論 (communication theory) 做出重要貢獻的數學家。他的名字與奈奎斯特採樣定理等重要概念緊密相連。
這兩位科學家的工作對於理解和發展語音編碼以及整個數位通訊領域都至關重要。香農的資訊理論提供了量化資訊和資訊傳輸能力的框架,而奈奎斯特的工作則奠定了數位信號處理和採樣的基礎。
語音編碼器 (Speech Coders) 的分類體系 (Taxonomy)
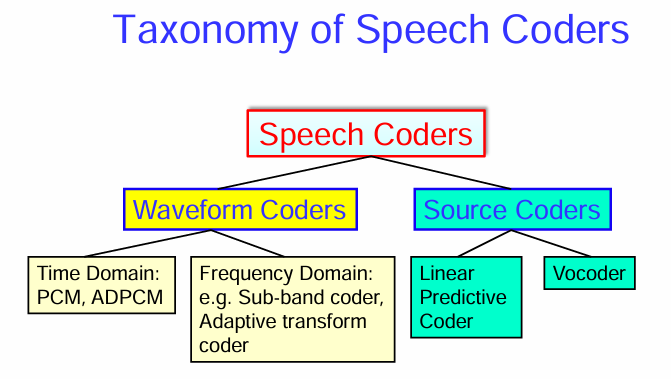
音編碼器主要可以分為兩大類:波形編碼器 (Waveform Coders) 和 源編碼器 (Source Coders)。
1. 波形編碼器 (Waveform Coders):
目標是盡可能地精確地重建原始語音訊號的波形。
這類編碼器試圖保留語音訊號的所有成分,而不依賴於特定的語音產生模型。
通常可以適用於各種語音和音頻訊號,但壓縮率相對較低。
波形編碼器又可以進一步分為:
時域 (Time Domain): 直接在時域對語音波形進行編碼。常見的例子包括:
- 脈衝碼調製 (Pulse Code Modulation, PCM): 直接對語音訊號的幅度進行量化編碼。
- 自適應差分脈衝碼調製 (Adaptive Differential Pulse Code Modulation, ADPCM): 對語音訊號的差分值(相鄰取樣點之間的差異)進行量化編碼,並根據訊號特性自適應地調整量化步長。
頻域 (Frequency Domain): 將語音訊號轉換到頻域進行編碼。常見的例子包括:
- 子帶編碼器 (Sub-band coder): 將語音頻帶劃分為若干個子帶,並對每個子帶的訊號進行獨立編碼。
- 自適應變換編碼器 (Adaptive transform coder): 使用時頻變換(如離散餘弦變換 DCT)將語音訊號轉換到頻域,然後對變換係數進行量化和編碼,並根據訊號特性自適應地調整編碼策略。
2. 源編碼器 (Source Coders):
目標是提取語音訊號的本質參數,這些參數基於人類語音產生的模型。
編碼器分析語音訊號,提取模型參數(例如聲道的共振峰頻率、基音週期、濁音/清音判決等),然後對這些參數進行編碼和傳輸。
在解碼端,使用這些參數合成語音訊號。
源編碼器的壓縮率通常比波形編碼器高,但合成的語音質量可能不如波形編碼器。
常見的例子包括:
線性預測編碼器 (Linear Predictive Coder, LPC): 基於線性預測模型分析語音,提取預測係數和激勵信號的參數。
聲碼器 (Vocoder): 一種更早期的源編碼器,通常將語音頻譜劃分為若干個頻帶,並傳輸每個頻帶的能量以及基音週期等信息。
總而言之,語音編碼器可以根據其編碼目標分為波形編碼器(力求精確重建波形)和源編碼器(力求提取並編碼語音產生的本質參數)。這兩大類編碼器在壓縮率和合成語音質量方面各有優劣,適用於不同的應用場景。
衡量語音編碼品質 (Measure of Quality) 的兩種主要方法

位元率 (Bit rate) 和 平均意見分數 (Mean Opinion Score, MOS),並提到了另一個客觀指標 訊號雜訊比 (Signal-to-Noise Ratio, SNR)。
位元率與品質的關係:
- 位元率和品質密切相關 (Bit rate and quality are intimately related): 通常情況下,用於表示語音的位元率越高,編碼後的語音品質也越高。
- 位元率越低,品質越低 (lower the bit rate, lower the quality): 相反,為了實現更高的壓縮率(更低的位元率),通常需要犧牲一些語音品質。
平均意見分數 (MOS):
MOS 是最廣泛使用的主觀品質衡量標準 (the most widely used measure of quality is the Mean Opinion Score (MOS))。
由於語音品質最終是由人類聽覺感知的,因此主觀評估非常重要。MOS 通過讓多個聽者對編碼後的語音進行評分來獲得。
評分標準: 通常使用一個 5 分制的等級:
- 5: Excellent (極好)
- 4: Good (好)
- 3: Fair (尚可)
- 2: Poor (差)
- 1: Bad (極差)
MOS 值是對所有聽者評分的平均值,它提供了一個對編碼器整體感知品質的量化指標。
訊號雜訊比 (SNR):

總而言之,衡量語音編碼品質需要結合主觀和客觀的方法。MOS 是最常用的主觀評估方法,直接反映人類的聽覺感受。SNR 是一個常用的客觀指標,衡量訊號與雜訊的相對強度。位元率則是影響品質的一個重要因素
純量波形編碼器 (Scalar Waveform Coders)

這是波形編碼器的一個子類別。
純量波形編碼器的概念:
純量 (Scalar): 指的是編碼過程是逐個取樣點 (sample-by-sample) 進行的,每個語音取樣點都被獨立地量化和編碼,而不考慮相鄰取樣點之間的相關性。
波形編碼器 (Waveform Coders): 如前所述,這類編碼器的目標是盡可能精確地重建原始語音訊號的波形。
常見的純量波形編碼技術:
圖片列舉了幾種常見的純量波形編碼技術:
線性脈衝碼調製 (Linear PCM): 最基本的數位語音編碼方法。直接對每個語音取樣點的幅度進行線性量化,並用固定位數的二進制碼表示。
μ-law PCM (μ-law companding): 一種非線性 PCM 技術,主要應用於北美和日本的電話系統。它在編碼前對語音訊號進行非線性壓縮 (companding),以改善低幅度訊號的量化信噪比,並在解碼後進行相應的擴展 (expanding)。
A-law PCM (A-law companding): 另一種非線性 PCM 技術,主要應用於歐洲和世界其他地區的電話系統。與 μ-law 類似,它也使用非線性壓縮來優化量化性能。
自適應預測編碼 (Adaptive Predictive Coding, APCM): 雖然名稱中包含「預測」,但這裡通常指的是自適應量化 (adaptive PCM)。量化步長會根據輸入訊號的局部特性進行調整,以提高編碼效率。
差分脈衝碼調製 (Differential Pulse Code Modulation, DPCM): 利用語音訊號相鄰取樣點之間的高度相關性,對當前取樣點與其預測值之間的差分值進行量化編碼,而不是直接量化原始取樣點。這可以降低編碼所需的位元率。
增量調製 (Delta Modulation, DM): 一種簡化的 DPCM,使用 1 位元量化器來表示當前取樣點相對於前一個取樣點的變化趨勢(增加或減少一個固定的步長)。
簡而言之,純量波形編碼器是逐個取樣點進行編碼的波形編碼技術。上述列舉的方法通過不同的量化策略(線性或非線性、固定或自適應)以及利用取樣點之間的差分來實現語音訊號的數位化表示。
線性脈衝碼調製 (Linear Pulse Code Modulation, PCM)
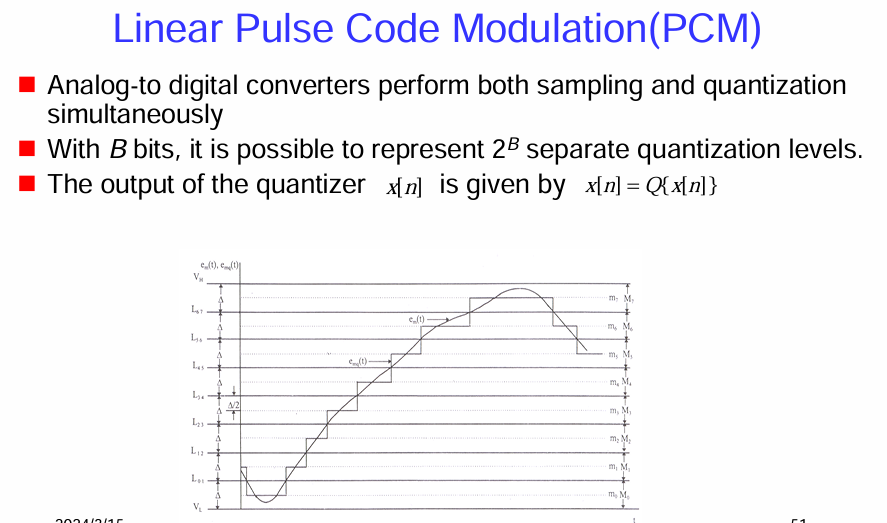
這是最基礎的數位語音編碼方法之一。
線性 PCM 的基本原理:
類比到數位轉換 (Analog-to-digital converters perform both sampling and quantization simultaneously): 類比語音訊號首先經過取樣 (sampling) 轉換為離散時間訊號,然後通過量化 (quantization) 將連續幅度的取樣值近似為有限個離散的量化級別。這兩個步驟通常由類比到數位轉換器 (ADC) 同時完成。
量化級別 (Quantization levels): 如果使用 B 個位元來表示每個量化後的取樣點,那麼可以表示
個不同的量化級別。位元數 B 決定了量化的精度和動態範圍。 量化器的輸出 (Output of the quantizer): 量化器的輸出
是對原始取樣值 x[n] 的量化近似,表示為 ,其中 Q{⋅} 代表量化操作。
圖示說明:
下方的圖示展示了線性 PCM 的量化過程:
- 連續時間訊號 (Continuous-time signal): 圖中的曲線 x(t) 代表原始的類比語音訊號。
- 取樣點 (Sampling points): 在時間軸上以固定的間隔進行取樣,得到離散時間的取樣值。
- 量化級別 (Quantization levels): 水平的虛線
表示不同的量化級別。這些級別是均勻分佈的,這就是「線性」的含義。 - 量化 (Quantization): 每個取樣值被映射到最接近的量化級別。例如,圖中曲線上的每個取樣點都被近似到最近的水平線。
- 量化誤差 (Quantization error): 量化後的階梯波形
與原始訊號 x(t) 之間存在差異,這就是量化誤差 。量化誤差的大小取決於量化步長 Δ(相鄰量化級別之間的間距)。
線性 PCM 的特點:
- 簡單直接: 原理簡單,易於實現。
- 固定位元率: 每個取樣點使用固定的位元數表示,因此位元率是固定的(取樣率 × 每取樣點位元數)。
- 量化雜訊: 由於量化過程引入了誤差,會產生量化雜訊。量化步長越大(位元數越少),量化雜訊越大,語音品質越低。
- 動態範圍受限: 固定位數的量化器具有有限的動態範圍。對於幅度變化較大的語音訊號,可能需要更多的位元才能避免削波失真。
總而言之,線性 PCM 是一種基本的數位語音編碼方法,通過對語音訊號進行均勻量化來實現數位表示。其品質直接取決於量化位元數,位元數越多,量化越精細,語音品質越高,但位元率也越高。
μ-law PCM (μ-律 PCM) 和 A-law PCM (A-律 PCM)
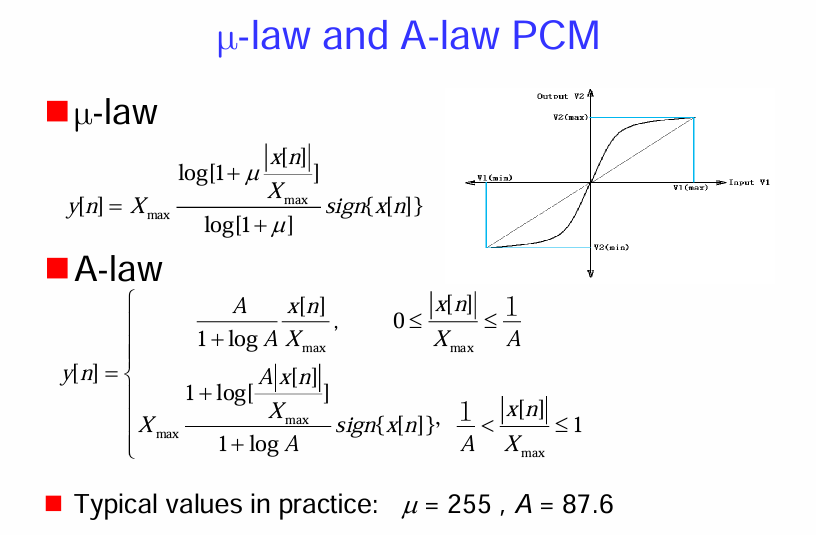
這兩種方法通過在量化前對語音訊號進行非線性壓縮,來改善低幅度訊號的量化信噪比,從而提高整體感知品質。
μ-law PCM:

A-law PCM:

圖示:
- 右上角的圖示比較了線性量化(虛線)和非線性量化(實線)的輸入-輸出特性。可以看到,非線性量化在接近零幅度時斜率較大,表示較小的輸入變化會導致較大的輸出變化,即量化步長較小,精度較高。而在高幅度區域,斜率較小,表示較大的輸入變化才導致較大的輸出變化,即量化步長較大。
實際應用中的典型值:
- μ 的典型值為 255。
- A 的典型值為 87.6。
總而言之,μ-律 PCM 和 A-律 PCM 是通過非線性壓縮來改善語音訊號量化性能的常用技術。它們在低幅度區域提供更高的量化精度,從而提高了編碼後的感知品質,特別是在位元率受限的電話系統中得到了廣泛應用。
增量調製 (Delta Modulation, DM)
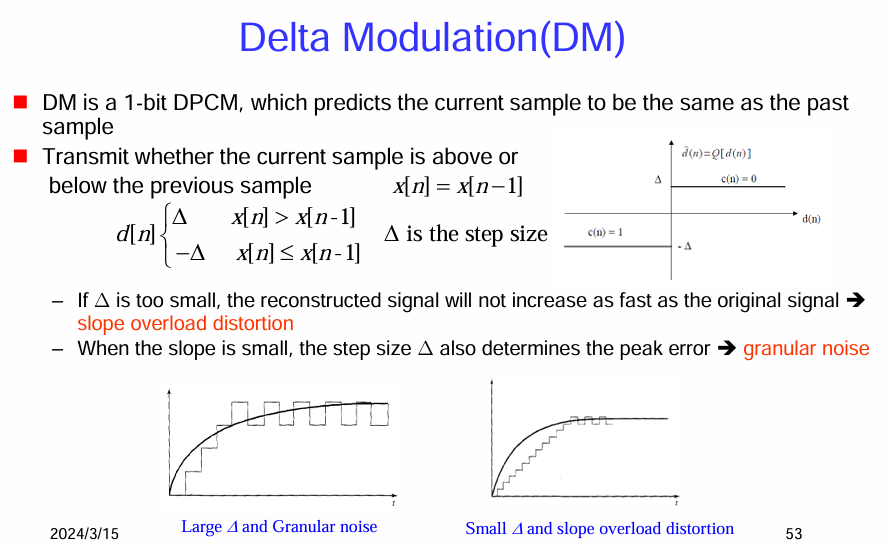
這是一種簡化的差分脈衝碼調製 (DPCM) 技術。
增量調製 (DM) 的基本原理:

圖示說明:

DM 的缺點:

總而言之,增量調製 (DM) 是一種簡單的 1 位元差分編碼技術,它只傳輸當前取樣點相對於前一個取樣點的變化方向。DM 的性能受到步長 Δ 的限制,過大的步長會導致粒狀雜訊,而過小的步長會導致斜率過載失真。
聲碼器 (Vocoder)
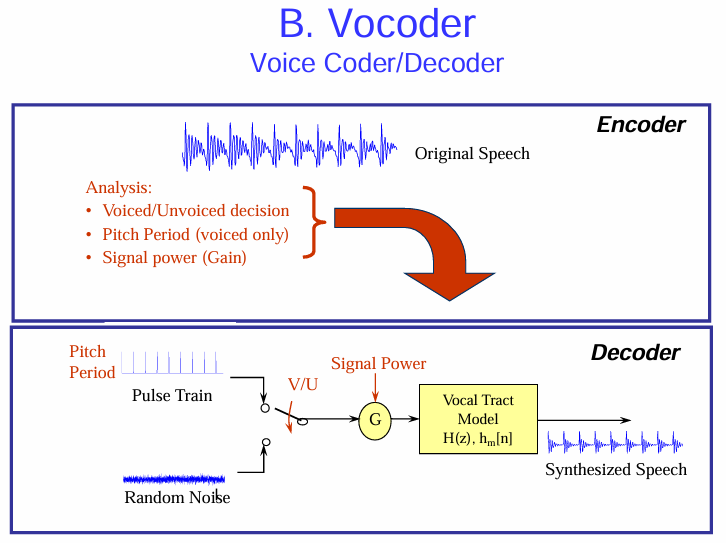
它是一種典型的源編碼器 (Source Coder),旨在通過分析和合成語音產生的關鍵參數來實現高壓縮率。
聲碼器 (Voice Coder/Decoder):
聲碼器的工作流程主要分為編碼 (Encoder) 和解碼 (Decoder) 兩個部分。
編碼器 (Encoder):
解碼器 (Decoder):

聲碼器的特點:
- 高壓縮率: 由於只傳輸語音產生的模型參數,因此可以實現比波形編碼器更高的壓縮率。
- 合成語音質量: 合成的語音質量通常不如波形編碼器,聽起來可能帶有一些機械感或人工合成的痕跡,因為它依賴於對語音產生過程的簡化模型。
總而言之,聲碼器是一種通過分析語音的產生機制,提*取關鍵參數並在解碼端使用這些參數合成語音的源編碼技術。它以犧牲一定的語音質量為代價,實現了較高的壓縮率。
線性預測編碼聲碼器 (LPC Vocoder)

LPC 聲碼器的概念:

LPC 聲碼器編碼器需要傳輸的參數:
- 增益 (Gain): 表示語音訊號的能量或幅度。
- LPC 係數 (LPC coefficients): 描述聲道模型的頻率響應特性,包括共振峰的位置和帶寬。
- 濁音/清音判決 (Voiced/unvoiced decision): 指示當前語音幀是濁音還是清音。
- 基音週期 (Pitch period P) (僅針對濁音幀): 如果當前幀是濁音,則需要傳輸聲帶振動的週期。
LPC 聲碼器的工作方式與一般的聲碼器類似:
- 編碼端: 輸入語音被分幀處理。對於每一幀,編碼器分析並提取增益、LPC 係數、濁音/清音判決以及基音週期(如果是濁音)。這些參數被量化和編碼後傳輸。
- 解碼端: 解碼器根據接收到的參數合成語音。對於濁音幀,使用基音週期產生脈衝序列作為激勵訊號;對於清音幀,則產生隨機雜訊作為激勵訊號。激勵訊號通過由接收到的 LPC 係數構成的聲道模型濾波器進行濾波,並根據接收到的增益進行幅度調整,最終合成語音。
LPC 聲碼器的特點:

總而言之,LPC 聲碼器是一種利用線性預測編碼技術來建模聲道的源編碼器。編碼器提取並傳輸增益、LPC 係數、濁音/清音判決和基音週期等參數,解碼器則利用這些參數合成語音。
Part 4- Speech Synthesis
四種不同的語音生成 (speech generation) 方法
四種語音生成方法:
有限域波形拼接 (Limited-domain waveform concatenation): 這種方法適用於語音內容受限的特定應用,例如報時或簡單的語音提示。它預先錄製了所有需要的詞語或音節,然後根據需要將這些預錄製的波形片段直接拼接起來形成語音輸出。由於語料庫有限,合成的語音在這些限定的語句內通常聽起來比較自然。
無波形修改的拼接合成 (Concatenative synthesis with no waveform modification): 這種方法使用一個較大的語音資料庫,其中包含了各種音素、雙音子、三音子甚至更長的語音單元。為了合成新的語句,系統從資料庫中選擇並拼接相應的語音單元。由於拼接時不對原始波形進行修改,合成語音的自然度在很大程度上取決於資料庫的質量和拼接點的平滑處理。
帶波形修改的拼接合成 (Concatenative systems with waveform modification): 這種方法在拼接語音單元時,允許對波形進行一定的修改,例如調整音高 (pitch)、語速 (speaking rate) 和持續時間 (duration),以更好地適應目標語句的韻律需求。常用的波形修改技術包括 PSOLA (Pitch Synchronous Overlap and Add) 等。通過波形修改,可以提高合成語音的自然度和表現力。
基於規則的系統 (Rule-based systems): 這種方法不依賴於預先錄製的語音資料庫。相反,它基於一套語言學規則(例如發音規則、韻律規則)和一個聲學模型(描述不同語音單元的聲學特性)來合成語音。當需要合成一個新的語句時,系統根據規則生成目標語音的聲學參數(例如音高、持續時間、頻譜包絡),然後使用聲學模型將這些參數轉換為可聽的語音波形。早期的語音合成系統大多基於規則,但由於其合成的語音通常聽起來比較機械和不自然,現在更多地被拼接合成和統計參數語音合成等方法所取代。
總而言之,這四種語音生成方法代表了語音合成技術發展的不同階段和方向。從直接拼接預錄製的片段到基於規則生成聲學參數,再到利用大量語音資料進行統計建模,語音合成的目標一直是生成更自然、更具表現力的語音。
拼接語音合成 (Concatenative Speech Synthesis)

這是語音生成中常用的一種方法。
拼接語音合成的基本原理:

共發音的影響 (Speech segments are greatly affected by coarticulation):
可能出現的不連續性 (There can be spectral or prosodic discontinuities):
在拼接不同的語音片段時,可能會出現以下不連續性,影響合成語音的自然度:

為了克服這些不連續性,更複雜的拼接合成系統會採用各種技術,例如:

總而言之,拼接語音合成是一種通過從預錄製的語音資料庫中選擇並拼接相應的語音片段來合成語音的方法。共發音是影響合成語音自然度的重要因素,而頻譜和韻律上的不連續性是拼接合成需要解決的主要問題。
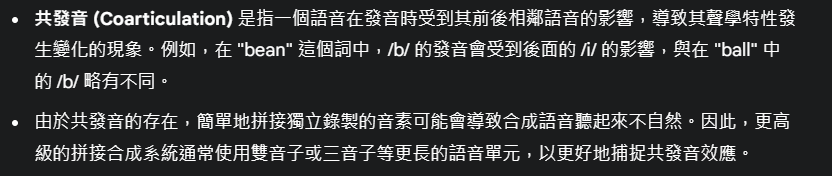
基於隱馬爾可夫模型 (Hidden Markov Model, HMM) 的語音合成 (HMM-Based Speech Synthesis)
這是一種統計參數語音合成方法,與拼接合成不同,它不直接使用預錄製的波形片段,而是利用統計模型來生成語音的聲學參數。
HMM-Based Speech Synthesis 的基本原理:
HMM-Based Speech Synthesis 主要包括訓練 (Training) 和合成 (Synthesis) 兩個部分。
1. 訓練部分 (Training part - 上半部分):

2. 合成部分 (Synthesis part - 下半部分):

HMM-Based Speech Synthesis 的特點:

總而言之,HMM-Based Speech Synthesis 是一種基於統計模型的語音合成方法。它通過訓練 HMMs 來學習語音的聲學特性和時間動態,然後根據輸入文本生成聲學參數,並使用聲碼器合成最終的語音波形。
Part 5- Automatic Speech Recognition
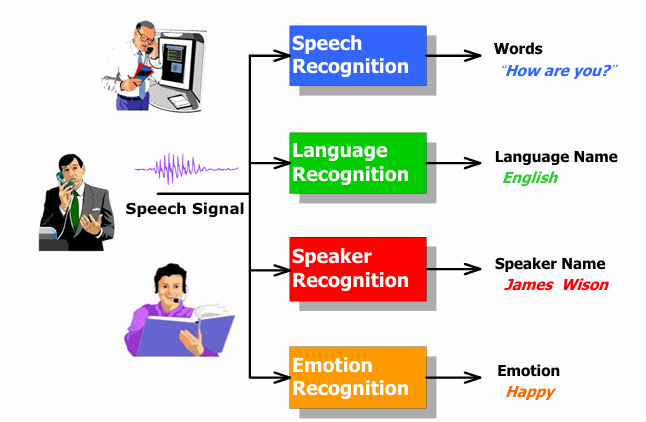
雜訊通道模型 (The Noisy Channel Model)
自動語音辨識 (ASR) 的定義:
- 自動語音辨識是一個將聲學語音訊號轉換成一串詞語的過程。
雜訊通道模型:


總而言之,雜訊通道模型是自動語音辨識中一個非常重要的理論框架。它將語音辨識視為一個從帶有雜訊的聲學訊號中恢復出原始意圖的過程,並通過結合聲學模型和語言模型來做出最佳的猜測。

這張圖片延續了對 雜訊通道模型 (The Noisy Channel Model) 在自動語音辨識 (ASR) 中的應用的解釋,並明確了 ASR 的目標以及如何利用貝氏定理來實現這個目標。
ASR 的目標:

將聲學輸入視為觀察序列:

將句子視為詞序列:
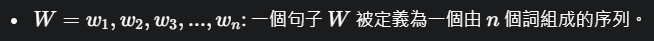
利用貝氏定理尋找最可能的句子:


總而言之,這張圖片清晰地闡述了 ASR 的目標是找到在給定聲學輸入下最有可能的句子,並解釋了如何通過應用貝氏定理,將這個目標轉化為最大化聲學模型和語言模型得分的乘積。
典型的語音辨識架構 (Speech Recognition Architecture)
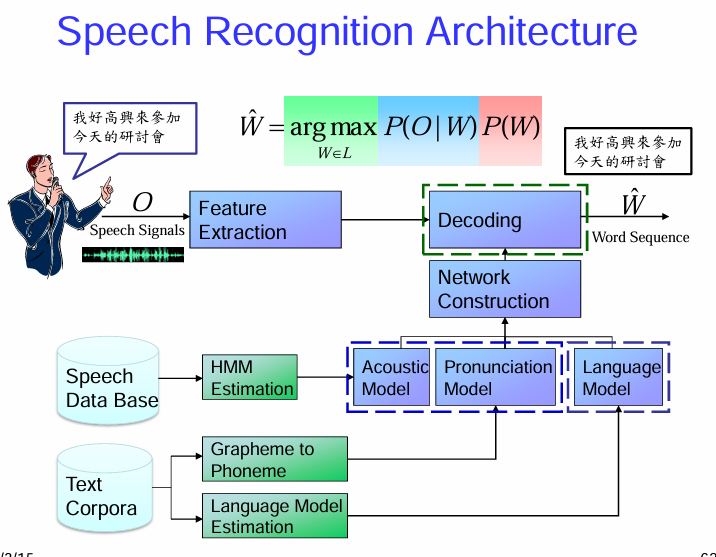
語音辨識的整體流程:

模型訓練的流程(通常是離線進行):

模型在解碼過程中的應用:

總而言之,一個典型的語音辨識系統首先通過特徵提取將聲學訊號轉換為特徵序列,然後利用預先訓練好的聲學模型、發音模型和語言模型,在解碼器中搜索出最有可能的詞序列作為辨識結果。模型訓練通常需要大量的語音和文本資料。
大詞彙量連續語音辨識 (Large Vocabulary Continuous Speech Recognition, LVCSR) 系統的架構
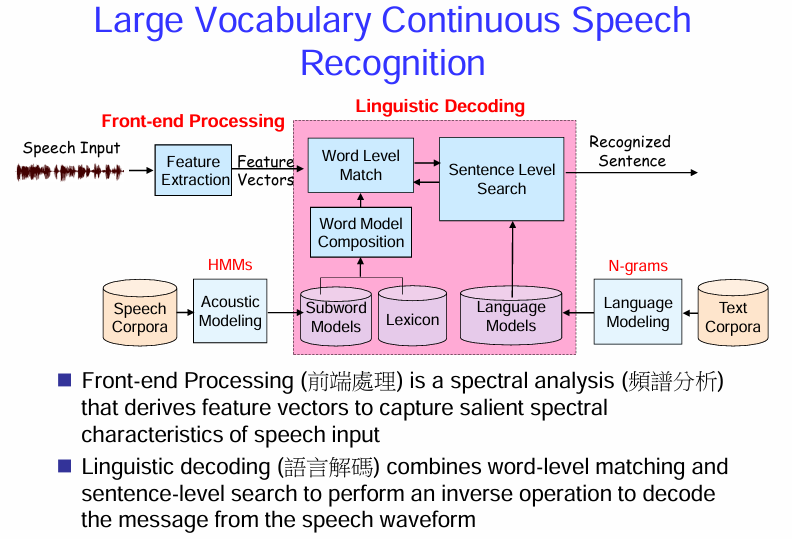
LVCSR 旨在辨識包含大量詞彙並且語音是連續的(沒有明顯停頓)語音。
LVCSR 系統架構:
LVCSR 系統通常包含以下幾個主要部分:
前端處理 (Front-end Processing):
- 語音輸入 (Speech Input): 接收原始的聲學語音訊號。
- 特徵提取 (Feature Extraction): 對語音訊號進行聲學分析(頻譜分析),提取出能夠表徵語音訊號重要頻譜特性的特徵向量序列。例如,MFCCs (梅爾頻率倒譜係數) 是常用的特徵。
聲學模型 (Acoustic Modeling):
- 語音語料庫 (Speech Corpora): 大量的帶有文本標註的語音資料,用於訓練聲學模型。
- HMMs (Hidden Markov Models): 聲學模型通常基於隱馬爾可夫模型。每個音素或更小的語音單元(如音子狀態)都用一個 HMM 來建模。HMM 描述了這些單元在時間上的聲學變化。
- Subword Models (子詞模型): 為了處理大詞彙量,通常使用比音素更小的子詞單元(如音節、半音節、詞素)來建模,以減少模型數量並提高泛化能力。
- Lexicon (詞典): 包含系統詞彙表中所有詞語及其發音(音素序列或子詞序列)。詞典將詞彙層次與底層的聲學模型單元連接起來。
- Word Model Composition (詞模型組合): 在辨識過程中,根據詞典中的發音,將子詞模型組合成詞模型。
語言模型 (Language Modeling):
- 文本語料庫 (Text Corpora): 大量的文本資料,用於訓練語言模型。
- Language Models (語言模型): 統計模型,用於預測詞語序列在語言中出現的概率。常用的語言模型是 N-gram 模型,它基於前 N-1 個詞預測下一個詞的概率。
- N-grams: 語言模型通常以 N-gram 的形式存在,記錄了詞語序列的統計信息。
語言解碼 (Linguistic Decoding):
- Word Level Match (詞級匹配): 將輸入的聲學特徵序列與詞模型進行匹配,計算每個詞語在不同時間點上的聲學得分。
- Sentence Level Search (句子級搜索): 利用聲學得分和語言模型提供的詞序列概率,在所有可能的詞序列中搜索出最有可能的辨識結果 (Recognized Sentence)。這個搜索過程通常使用維特比算法等搜索策略。
關鍵概念解釋:
- 前端處理 (Front-end Processing): 是一個頻譜分析過程,旨在提取能夠捕捉語音輸入顯著頻譜特性的特徵向量。
- 語言解碼 (Linguistic Decoding): 結合詞級匹配和句子級搜索,執行一個逆向操作,從語音波形中解碼出消息(即辨識出的詞序列)。
總而言之,LVCSR 系統通過前端處理提取語音特徵,利用聲學模型(基於 HMM 和子詞單元)和語言模型(基於 N-gram 等)來建模語音的聲學和語言規律,最後通過解碼器在巨大的搜索空間中找到最符合輸入語音的詞序列。
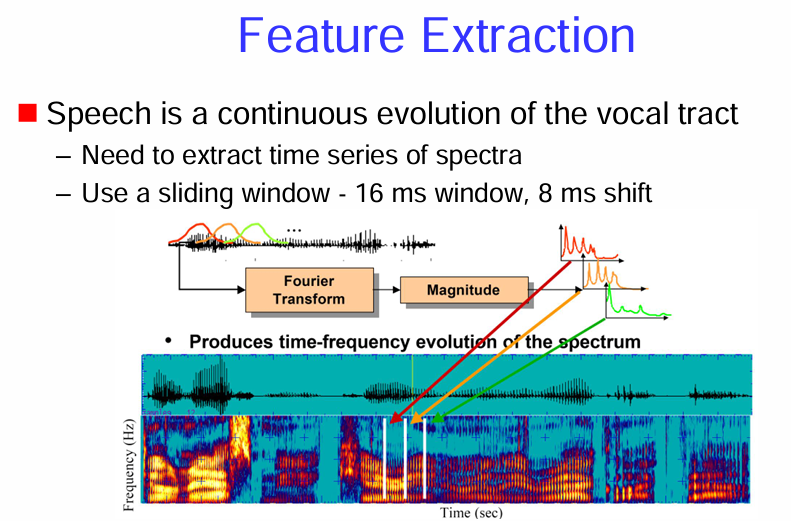
特徵提取 (Feature Extraction)
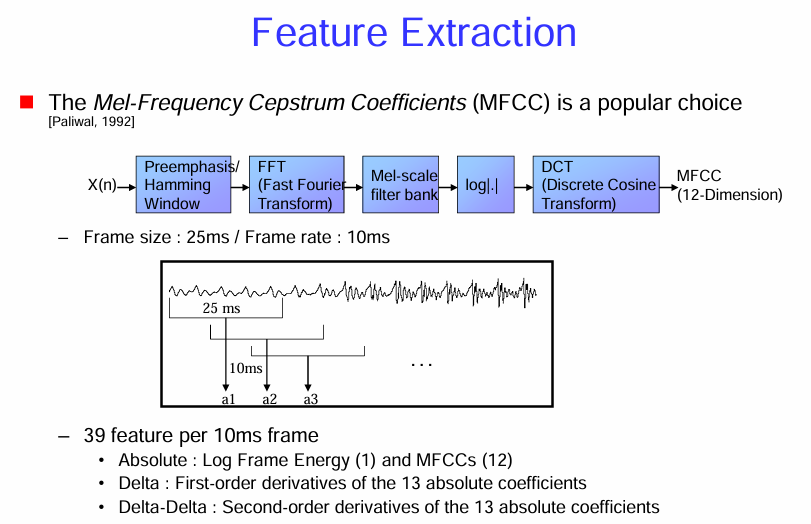
梅爾頻率倒譜係數 (MFCC):
- 流行選擇 (The Mel-Frequency Cepstrum Coefficients (MFCC) is a popular choice): MFCC 因其能夠較好地模擬人類聽覺系統的特性,並且在語音辨識任務中表現出色,而成為廣泛使用的聲學特徵。
MFCC 的提取流程:
圖中展示了從輸入語音訊號 x(n) 中提取 MFCC 的典型步驟:
- 預加重 (Preemphasis): 對輸入語音訊號進行高頻提升,以補償語音訊號在高頻部分的衰減,並增強高頻信息。通常使用一個一階高通濾波器。
- 分幀和加窗 (Framing / Hamming Window): 將連續的語音訊號分割成短時間幀(例如 25 毫秒),並對每一幀應用一個窗函數(例如漢明窗),以減少幀邊界的效應,平滑頻譜。
- 幀長 (Frame size): 通常為 20-30 毫秒。
- 幀移 (Frame rate): 相鄰兩幀之間的時間間隔(例如 10 毫秒)。幀移通常小於幀長,使得相鄰幀之間有重疊。
- 快速傅立葉轉換 (FFT (Fast Fourier Transform)): 對每一幀的加窗訊號進行快速傅立葉轉換,得到頻譜。
- 梅爾尺度濾波器組 (Mel-scale filter bank): 將頻譜通過一組在梅爾頻率尺度上均勻分佈的三角形帶通濾波器。梅爾尺度是一種模擬人類聽覺系統對不同頻率感知敏感度的非線性尺度。低頻部分濾波器密集,高頻部分濾波器稀疏。
- 取對數 (log|.|): 對每個梅爾尺度濾波器輸出的能量取對數。這模擬了人類聽覺系統對聲音強度的非線性感知。
- 離散餘弦轉換 (DCT (Discrete Cosine Transform)): 對取對數後的梅爾尺度能量進行離散餘弦轉換。DCT 的目的是去除梅爾尺度濾波器組輸出之間的相關性,並將能量集中在少數低頻係數上。通常取前 12-13 個 DCT 係數作為 MFCC 特徵。
特徵維度:
- MFCC (12-Dimension): 通常提取 12 維或 13 維的 MFCC 係數(包括第 0 維,即對數能量)。
動態特徵:
為了捕捉語音訊號在時間上的動態變化,通常還會計算 MFCC 的一階差分(Delta)和二階差分(Delta-Delta)係數。
- Absolute: 絕對特徵,包括 1 維對數幀能量和 12 維 MFCCs,共 13 維。
- Delta (一階差分): 表示絕對特徵在時間上的變化率,通常有 13 維(對應於 13 個絕對特徵)。
- Delta-Delta (二階差分): 表示一階差分特徵在時間上的變化率,通常也有 13 維。
因此,對於每一幀語音,通常會提取總共 39 維的特徵向量(13 維絕對特徵 + 13 維一階差分 + 13 維二階差分)。
圖示說明:
- 下方的波形示意了語音訊號被分割成 25 毫秒的幀,並且相鄰幀之間有 10 毫秒的幀移。a1,a2,a3 等表示不同時間幀提取的特徵向量。
總而言之,MFCC 是一種廣泛應用的語音辨識特徵,它通過模擬人類聽覺系統的感知特性,提取語音訊號的頻譜包絡信息。提取過程包括預加重、分幀加窗、FFT、梅爾尺度濾波器組、取對數和 DCT 等步驟。為了捕捉語音的動態特性,通常還會計算 MFCC 的一階和二階差分。
基本語音單元 (Fundamental Speech Units) 的選擇

不同的基本語音單元:
類音素單元 (Phoneme-like units (PLUS)):
- 最簡單的基本語音單元集合 (The simplest set of fundamental speech units): 音素是語言中能夠區分意義的最小語音單位。使用音素作為基本單元可以減少需要建模的單元數量。
- 範例 (Example): 圖中列舉了一些英語的音素符號,例如 /s/ (嘶), /ɛ/ (短音 e), /l/ (邊音 l), /g/ (濁軟顎塞音), /m/ (雙唇鼻音), /ɑː/ (長音 ah), /n/ (齒齦鼻音), /t/ (齒齦塞音)。
非音素單元 (Units other than Phones):
- 音節 (Syllables): 音節是語音的基本結構單位,通常包含一個核心(通常是元音)和可選的起始和結尾輔音。使用音節作為單元可以更好地捕捉語音的韻律信息,但需要建模的單元數量會大大增加。範例:/sɛg/ (seg), /mɛn/ (men), /t/ (t)。
- 半音節 (Demisyllables): 半音節是音節的一部分,例如音節的起始部分或結尾部分。使用半音節可以在音素和音節之間取得平衡。範例:/sɛ/ (se), /ɛg/ (eg), /mɛ/ (me), /æn/ (an), /n/ (n), /t/ (t)。
帶有語言學上下文依賴的單元 (Units with Linguistic Context Dependency):
- 三音子 (Triphones): 三音子考慮了音素的上下文,即一個音素受到其前一個和後一個音素的影響。例如,在 “cat” 這個詞中,中間的 /æ/ 音素會受到前面的 /k/ 和後面的 /t/ 的影響,形成一個特定的三音子 /k-æ-t/。使用三音子可以更精確地建模共發音效應,顯著提高語音辨識和合成的性能,但需要建模的單元數量非常龐大,需要大量的訓練數據。
選擇基本語音單元的考量因素:
- 模型複雜度: 使用更小的單元(如音素)可以減少模型需要建模的數量,但可能無法充分捕捉語音的上下文變化。使用更大的單元(如音節)可以更好地捕捉韻律,但需要更多的模型。
- 數據需求: 更精細的單元(如三音子)需要大量的訓練數據才能可靠地估計模型參數。
- 共發音建模能力: 考慮上下文的單元(如三音子)能更好地處理共發音現象,提高語音的自然度。
- 泛化能力: 對於訓練數據中未出現的語音組合,基於更小單元的模型可能具有更好的泛化能力。
總而言之,選擇合適的基本語音單元是語音處理中的一個重要決策,需要在模型複雜度、數據需求、共發音建模能力和泛化能力之間進行權衡。音素是最簡單的選擇,而三音子則考慮了上下文依賴,能更精確地建模語音。音節和半音節則提供了介於兩者之間的選擇。
聲學模型 (Acoustic Model)
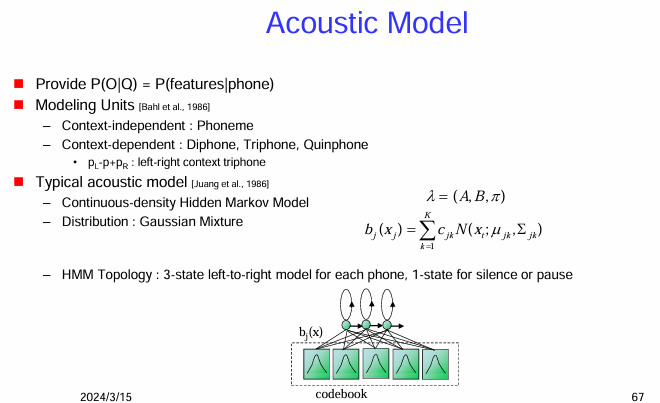
這是自動語音辨識系統的核心組件之一,用於計算給定音素(或更小的語音單元)產生觀察到的聲學特徵序列的機率。
聲學模型的核心功能:
- 提供 P(O|Q) = P(features|phone): 聲學模型的主要任務是計算在給定一個音素序列(或更一般的語音單元序列)Q 的情況下,觀察到的聲學特徵序列 O 的條件機率 P(O∣Q)。這裡的 O 通常是 MFCC 等特徵向量的序列,而 Q 則是音素、雙音子或三音子等語音單元的序列。
建模單元 (Modeling Units):
聲學模型可以使用不同層次的語音單元作為建模的基本單位:
- 上下文無關 (Context-independent): 音素 (Phoneme): 最簡單的建模單元,每個音素都用一個獨立的模型表示,不考慮其在語音序列中的上下文影響。
- 上下文相關 (Context-dependent): 雙音子 (Diphone), 三音子 (Triphone), 五音子 (Quinphone): 這些單元考慮了音素的上下文。三音子是最常用的上下文相關單元,它考慮了目標音素的前一個音素
和後一個音素 。例如,/k-æ-t/ 表示 /æ/ 這個音素出現在 /k/ 之後和 /t/ 之前。
典型的聲學模型:

HMM 拓撲結構 (HMM Topology):

圖示說明:
- 下方的示意圖展示了一個 HMM 的輸出概率計算過程。觀察到的聲學特徵向量被送入一個 碼本 (codebook),這個碼本實際上就是 GMM 的參數(均值和協方差矩陣)。HMM 的每個狀態都與這個碼本中的高斯分佈相關聯,並根據 GMM 計算出當前觀察向量屬於該狀態的概率
。
總而言之,聲學模型是語音辨識系統中用於將聲學特徵序列映射到語音單元序列的概率模型。連續密度隱馬爾可夫模型結合高斯混合模型是目前主流的聲學模型架構。模型使用上下文相關或無關的語音單元進行建模,並通過訓練大量的語音數據來估計模型參數。HMM 的拓撲結構通常採用左到右模型來模擬語音的時序特性。
發音模型 (Pronunciation Model)
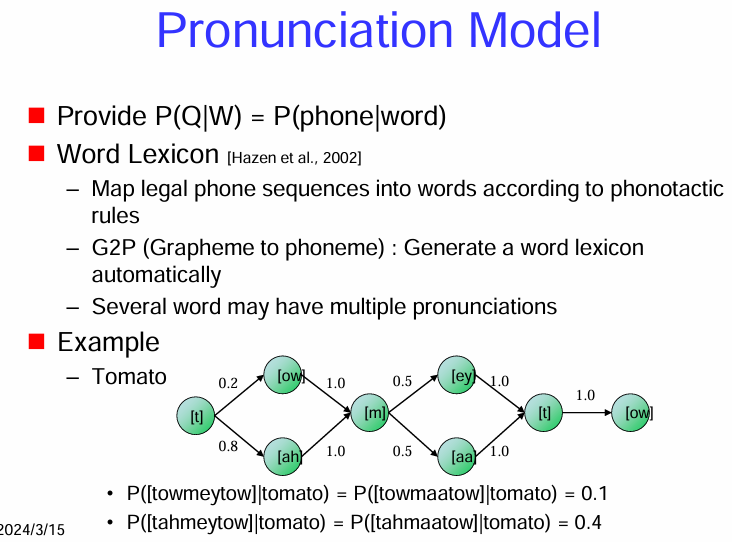
發音模型的核心功能:
- 提供 P(Q|W) = P(phone|word): 發音模型的主要任務是提供在給定一個詞語 W 的情況下,其可能的音素序列 Q 的條件機率 P(Q∣W)。換句話說,它描述了一個詞語可能有哪些不同的發音方式以及這些發音的可能性。
詞典 (Word Lexicon):
- 映射合法的音素序列到詞語 (Map legal phone sequences into words according to phonotactic rules): 發音模型的核心通常是一個詞典 (lexicon),它包含了系統詞彙表中的所有詞語,以及每個詞語對應的一個或多個可能的音素序列。詞典的構建需要遵循語言的音位規則 (phonotactic rules),即哪些音素可以合法地組合在一起形成詞語。
- 字素到音素 (G2P (Grapheme to phoneme)): 自動生成詞典 (Generate a word lexicon automatically): 對於大詞彙量系統,人工編寫所有詞語的發音可能非常耗時。因此,通常會使用字素到音素 (G2P) 模型來自動預測詞語的發音。G2P 模型基於詞語的拼寫 (字素序列) 來預測其可能的音素序列。這些模型通常使用統計方法(如決策樹、條件隨機場、序列到序列模型)進行訓練。
- 多個發音 (Several word may have multiple pronunciations): 許多詞語可能有多個合法的發音,這取決於說話人的口音、語速、語境等因素。發音模型需要考慮到這些變異性,並為每個可能的發音分配一個概率。
範例 (Example):

在語音辨識中的作用:
- 在語音辨識的解碼過程中,發音模型將辨識出的音素序列轉換為可能的詞語序列,並結合語言模型來判斷哪個詞序列最有可能。對於一個給定的音素序列,發音模型可以提供所有可能對應的詞語以及它們的概率。
總而言之,發音模型是語音辨識系統中至關重要的一環,它提供了詞語到音素序列的映射,考慮了詞語可能的多種發音方式以及它們的概率,從而幫助系統在聲學模型輸出的音素序列和語言模型預測的詞序列之間建立橋樑。
聲學模型 (HMM) 的訓練 (Training) 過程
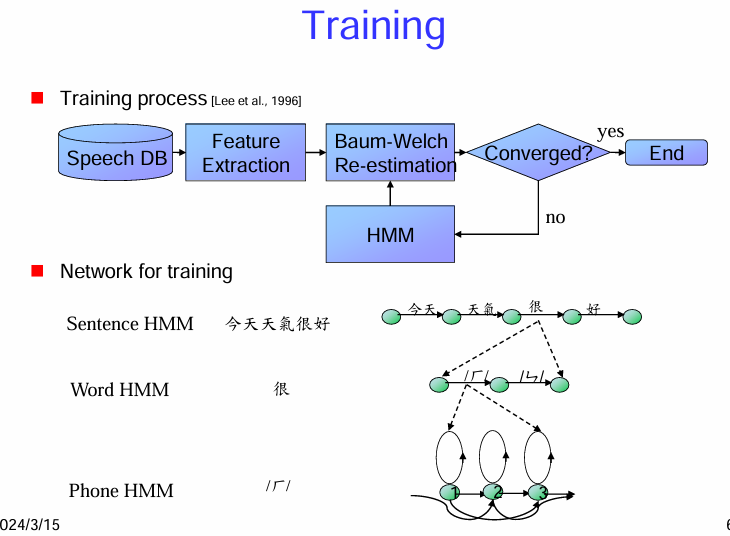
訓練過程 (Training process):
語音資料庫 (Speech DB): 訓練過程的輸入是大量的語音資料庫 (Speech Database),其中包含了錄製的語音訊號以及對應的文本標註(例如句子級別的轉錄)。
特徵提取 (Feature Extraction): 對語音資料庫中的每個語音檔案進行特徵提取 (Feature Extraction),將原始的聲學波形轉換成一系列的聲學特徵向量(例如 MFCCs)。
Baum-Welch 重估 (Baum-Welch Re-estimation): Baum-Welch 算法 是一種期望最大化 (Expectation-Maximization, EM) 算法,廣泛用於訓練 HMM 的參數。
- 初始化: 首先需要對 HMM 的參數(狀態轉移概率、輸出概率分佈的參數)進行初始化。可以隨機初始化,也可以使用一些啟發式方法。
- 迭代: Baum-Welch 算法通過迭代的方式來優化 HMM 的參數:
- 期望 (Expectation) 步驟: 給定當前的 HMM 參數和觀察到的聲學特徵序列,計算模型處於每個狀態的概率以及狀態之間轉移的概率。這通常使用前向-後向算法來完成。
- 最大化 (Maximization) 步驟: 基於期望步驟中計算得到的概率,重新估計 HMM 的參數,使得模型能夠更好地解釋觀察到的訓練數據。
- 收斂判斷 (Converged?): 在每次迭代後,會檢查模型的參數是否已經收斂(即參數的變化非常小)。如果收斂,則訓練過程結束。
- 繼續迭代 (no): 如果模型尚未收斂,則返回到 Baum-Welch 重估步驟進行下一次迭代。
HMM: 訓練完成後,得到最終的 隱馬爾可夫模型 (HMM)。這個模型包含了每個語音單元(例如音素)的聲學特性,並可以用於在語音辨識的解碼階段計算聲學得分。
語言模型 (Language Model)

言模型用於評估一個詞序列(即一個句子)在語言中出現的可能性,提供語法和語義上的約束,幫助辨識器從聲學上相似的候選詞序列中選擇最合理的結果。
語言模型的核心功能:

詞序列的機率計算:


語言模型的訓練:

利用 Tree-Copy Search 結合 Bigram/Trigram 語言模型 進行搜索
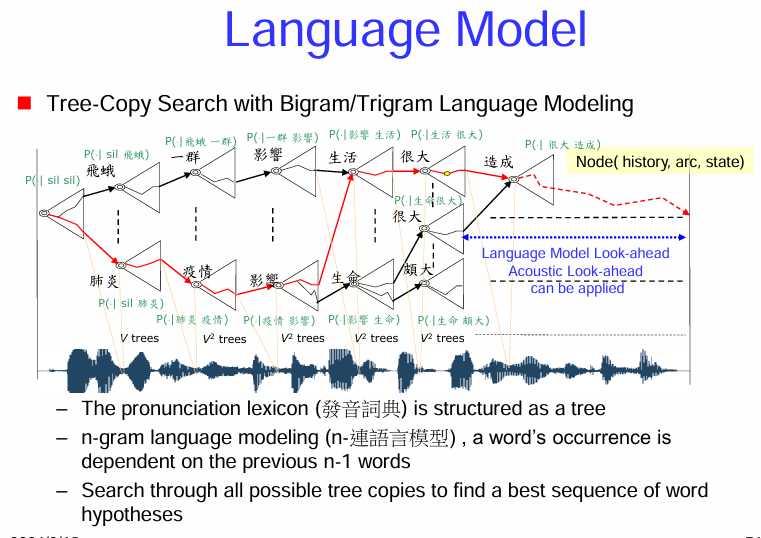
Tree-Copy Search 的概念:

圖示說明:


總而言之,Tree-Copy Search 是一種在語音辨識解碼過程中結合 N-gram 語言模型的方法。通過在詞彙樹中根據不同的詞語歷史複製搜索路徑,系統能夠在搜索時考慮到語言模型的上下文信息,從而找到最符合聲學證據和語言規律的詞序列。
搜索網路的構建 (Network Construction)
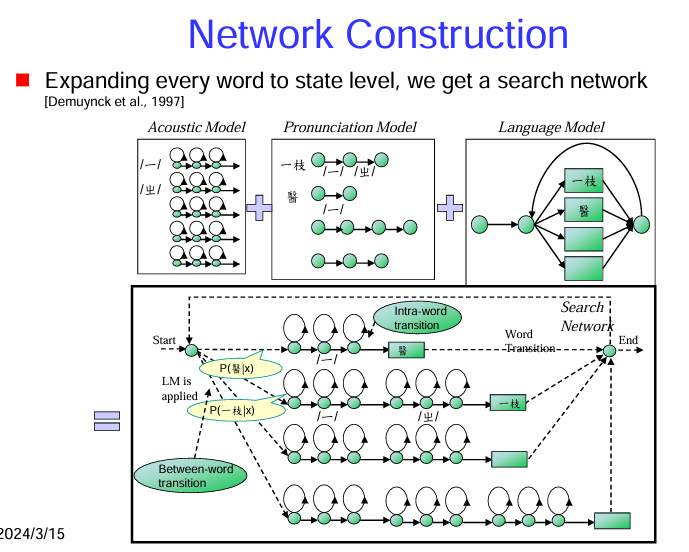
搜索網路的構建過程:

搜索網路的結構:

搜索過程:
- 解碼器在這個搜索網路中尋找從開始節點到結束節點的最佳路徑,這條最佳路徑對應於最有可能的詞序列(辨識結果)。搜索通常使用維特比算法或其他類似的動態規劃算法。算法在時間上逐步擴展搜索路徑,並在每個節點上保留具有最高累積分數的路徑。總得分是聲學模型得分和語言模型得分的加權和。
總而言之,搜索網路是語音辨識解碼器的核心數據結構。它將聲學模型、發音模型和語言模型的信息整合在一起,形成一個表示所有可能詞序列及其對應聲學和語言模型得分的圖。解碼器在這個網路中高效地搜索最佳路徑,以找到最符合輸入語音的詞序列。
語音辨識的解碼 (Decoding) 過程
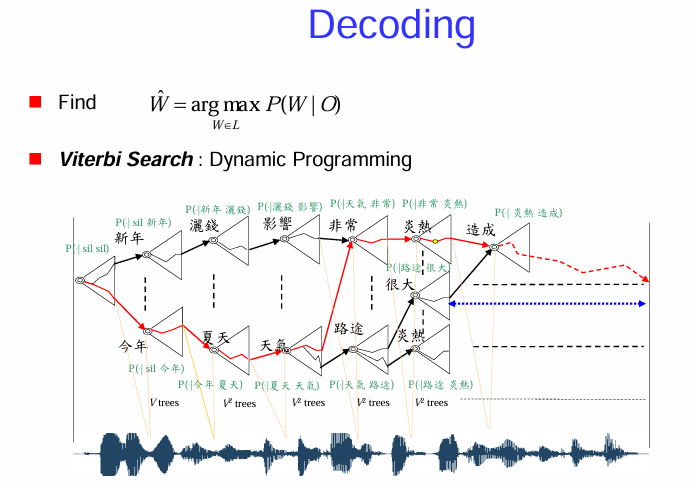
解碼的目標:

維特比搜索:動態規劃 (Viterbi Search : Dynamic Programming):

圖示說明:

維特比搜索的步驟簡化:

總而言之,維特比搜索是一種高效的動態規劃算法,用於在語音辨識的搜索網路中找到最有可能的詞序列。它通過在每個時間步保留最佳路徑並剪枝掉較差的路徑,有效地降低了搜索複雜度,並最終通過回溯得到辨識結果。